本节继续介绍RNN的使用场景,处理Seq2Seq任务。Seq2Seq任务,即从一个序列映射到另一个序列的任务。在生活中会有很多符合这样特性的例子:前面的语言模型、语音识别例子,都可以理解成一个Seq2Seq的例子,类似的应用还有机器翻译、词性标注、智能对话等。下面就来学一下Seq2Seq任务的处理方法。
Seq2Seq任务介绍
Seq2Seq(Sequence 2 Sequence)任务可以理解为,从一个Sequence做某些工作映射到(to)另外一个Sequence的任务,泛指一些Sequence到Sequence的映射问题。
Sequence可以理解为一个字符串序列,在给定一个字符串序列后,希望得到与之对应的另一个字符串序列(如翻译后的、语义上对应的)。Seq2Seq不关心输入和输出的序列是否长度对应。
Seq2Seq如果再细分,可以分成输入、输出序列不一一对应和一一对应两种。前面的语言模型就是一一对应的,类似的还有词性标注,可以用图9-26所示的网络结构来理解。如果给定的每个输入都会有对应的输出,这种情况使用简单的RNN模型就可以解决。
而输入输出序列不对应时会比较复杂一些,除了像前面语音识别模型中双向RNN+TensorFlow中的ctc_loss组合的方式之外,还有一种相对比较主流的解决方法——Encoder-Decoder框架。
Encoder-Decoder框架
1.Encoder-Decoder框架介绍
Encoder-Decoder框架的工作机制是:先使用Encoder将输入编码映射到语义空间(通过Encoder网络生成的特征向量),得到一个固定维数的向量,这个向量就表示输入的语义;
然后再使用Decoder将这个语义向量解码,获得所需要的输出。如果输出是文本,则Decoder通常就是语言模型。其内部结构如图9-27所示。
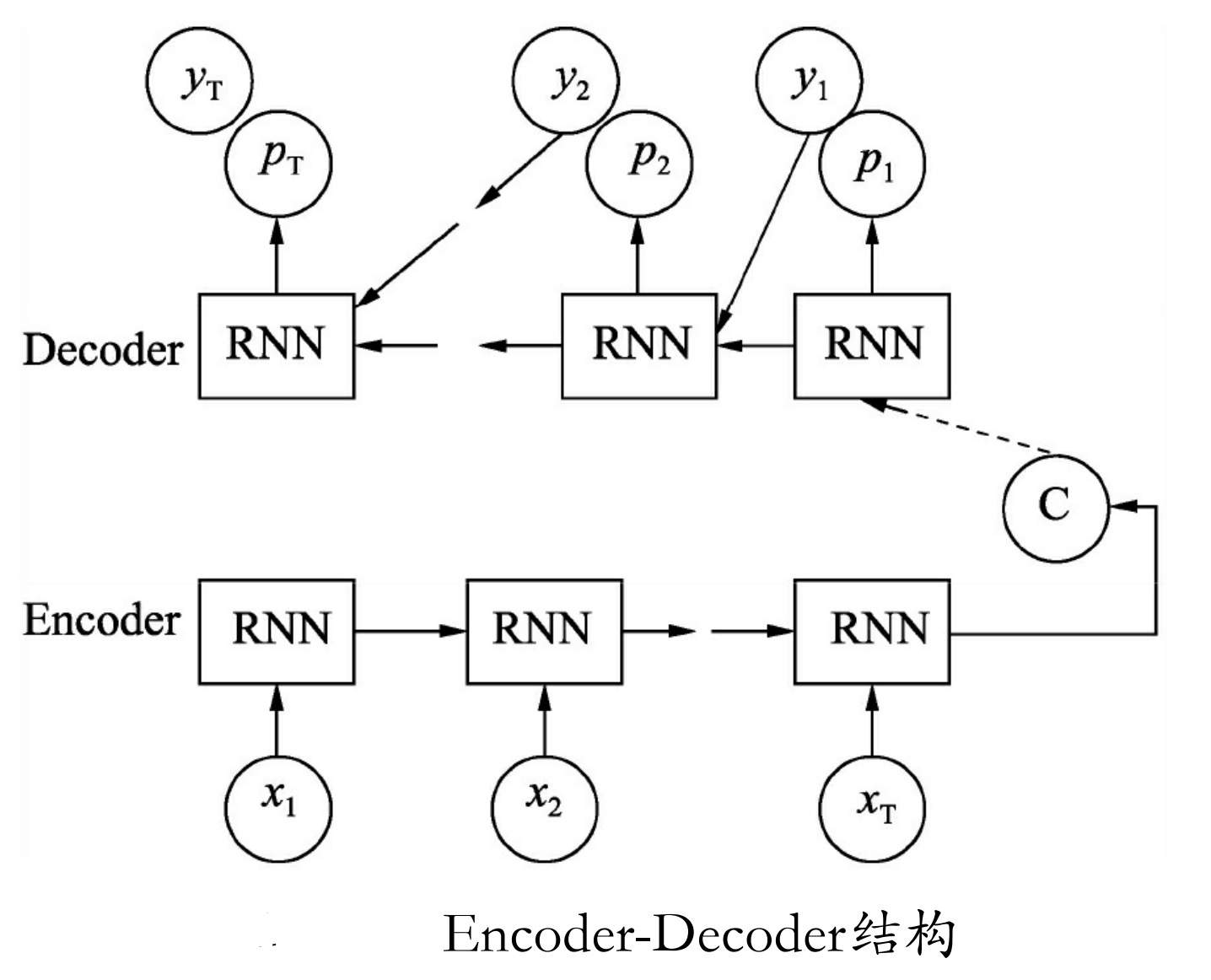
图9-27中Encoder-Decoder框架有两个输入:一个是x输入作为Encoder的输入,另一个是y输入作为Decoder输入,x和y依次按照各自的顺序传入网络。
可以看出在Seq2Seq的训练中,标签y既参与计算loss,又参与节点运算,而不是像前面学习的其他网络只用来做loss监督。在Encoder与Decoder之间的C节点就是码器Encoder输出的解码向量,将它作为解码Decoder中cell的初始状态,进行对输出的解码。
这种机制的优点如下:
非常灵活,并不限制Encoder、Decoder使用何种神经网络,也不限制输入和输出的内容(例如image caption任务,输入是图像,输出是文本)。
这是一个端到端(end-to-end)的过程,将语义理解和语言生成合在了一起,而不是分开处理。
2.TensorFlow中的Seq2Seq
在TensorFlow中有两套Seq2Seq的接口。
- 一套是
TensorFlow 1.0版本之前的旧接口。在tf.contrib.legacy_seq2seq下; - 另一套为
TensorFlow1.0版本之后推出的新接口,在tf.contrib.seq2seq下。
旧接口的功能相对简单,是静态展开的网络模型。而新接口的功能更加强大,使用的是动态展开的网络模型,并提供了训练和应用两种场景的Helper类封装。从使用角度来看,旧接口同样也是比较简单。而新接口会更加灵活,需要自己组建Encoder和Decoder并通过函数把它们手动连接起来。
为了便于理解,本书主要以旧接口中Seq2Seq框架来举例介绍。关于Seq2Seq的更多例子,及新接口的应用演示,可以参考如下网址中的实例:
https://github.com/ematvey/tensorflow-seq2seq-tutorials
旧接口中基本Seq2Seq函数的定义如下。
tf.contrib.legacy_seq2seq.basic_rnn_seq2seq(encoder_inputs,
decoder_inputs,
cell,
dtype=dtypes.float32,
scope=None)
参数说明如下。
- encoder_inputs:一个形状为
[batch_size xinput_size]的list。 - decoder_inputs:同encoder_inputs。
- cell:定义的cell网络。
- dtype:encoder_inputs和decoder_inputs中的类型(默认是tf.float32)。
- 返回值:outputs和state。
- outputs为
[batch_size,output_size]的张量; - state为
[batch_size,cell.state_size]; cell.state_size可以表示一个或者多个子cell的状态,视输入参数cell而定。
- outputs为
其函数的实现只有如下几行代码:
with variable_scope.variable_scope(scope or "basic_rnn_seq2seq"):
enc_cell = copy.deepcopy(cell)
_, enc_state = core_rnn.static_rnn(enc_cell, encoder_inputs, dtype=dtype)
return rnn_decoder(decoder_inputs, enc_state, cell)
现将传入的cell做一次深拷贝(deepcopy),用来当做Encoder的网络,将生成的结果和原来的cell再加上输入的decoder_inputs一起放到Decoder中,并输出生成结果。
注意: 在使用过程中,由于需要通过输入x来预测y,没有标签,这种情况就需要手动填充Decoder来代替训练时的标签。


