语言模型包括文法语言模型和统计语言模型。一般我们指的是统计语言模型。
统计语言模型
统计语言模型是指:把语言(词的序列)看作一个随机事件,并赋予相应的概率来描述其属于某种语言集合的可能性。
统计语言模型的作用是,为一个长度为 m 的字符串确定一个概率分布P(w1; w2; …;wm),表示其存在的可能性。其中,w1~wm 依次表示这段文本中的各个词。用一句话简单地说就是计算一个句子的概率大小。
用这种模型来衡量一个句子的合理性,概率越高,说明越符合人们说出来的自然句子,另一个用处是通过这些方法均可以保留住一定的词序信息,获得一个词的上下文信息。
词向量
前面的例子中可以看作是一个统计语言模型,所使用的词向量是one_hot编码,由于one_hot编码中所有的字都是独立的,所以该语言模型学到的词与词的上下文信息只能存放在网络节点中。而现实生活中,我们人类对字词的理解却并非如此,例如“手”和“脚”,会自然让人联想到人体的器官,而“墙”则与人体器官相差甚远。这表明本身的词与词之间是有远近关系的。如果让机器学习这种关系并能加以利用,那么便可以使机器像人一样理解语言的意义。
1、词向量解释
在神经网络中是通过一个描述词分布关系的方法来实现语义的理解,这种方法描述的词与one_hot描述的词都可以叫做词向量,但它还有个另外的名字叫word embedding(词嵌入)。
如何理解呢?将one_hot词向量中的每一个元素由整型改为浮点型,变为整个实数范围的表示;然后将原来稀疏的巨大维度压缩嵌入到一个更小维度的空间内,如图所示。
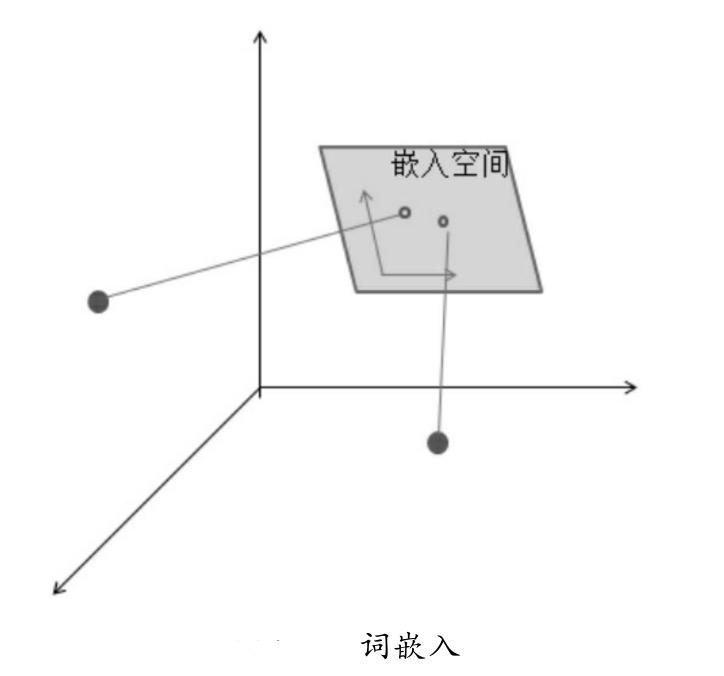
图中只举了个例子,将三维的向量映射到二维平面里。实际在语言模型中,常常是将二维的张量[batch,字的index]映射到多维空间[batch,embedding的index]。即,embedding中的元素将不再是一个字,而变成了字所转化的多维向量,所有向量之间是有距离远近关系的。
其实one_hot的映射也是这种方法,把每个字表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为0,只有一个维度的值为1,这个维度就代表了当前的字。one_hot映射与词嵌入的唯一区别就是仅仅将字符号化,不包含任何语义信息而已。
word embedding的映射方法是建立在分布假说(distributional hypothesis)基础上的,即假设词的语义由其上下文决定,上下文相似的词,其语义也相似。
词向量的核心步骤由两部分组成:
1、选择一种方式描述上下文。
2、选择一种模型刻画某个词(下文称“目标词”)与其上下文之间的关系。
一般来讲就是使用前面介绍的语言模型来完成这种任务。这类方法的最大优势在于可以表示复杂的上下文。
2、词向量训练
在神经网络训练的词嵌入(word embedding)中,一般会将所有的embedding随机初始化,然后在训练过程中不断更新embedding矩阵的值。对于每一个词与它对应向量的映射值,在TensorFlow中使用了一个叫tf.nn.embedding_lookup的方法来完成。
举例如下:
with tf.device("/cpu:0"):
embedding = tf.get_variable("embedding", [vocab_size, size])
inputs = tf.nn.embedding_lookup(embedding, input_data)
上面的代码先定义的embedding表示有vocab_size个词,每个词的向量个数为size个。最终得到的inputs就是输入向量input_data映射好的词向量了。比如input_data的形状为[batch_size,ndim],那么inputs就为[batch_size,ndim,size]。
注意:由于该词向量定义好之后是需要在训练中优化的,所以embedding 类型必须是tf.Variable,并且trainable=True(default)。
- embedding_lookup这个函数目前只支持在CPU上运行。
3、候选采样技术
对于语言模型相关问题,本质上还是属于多分类问题。对于多分类问题,一般的做法是在最后一层生成与类别相等维度的节点,然后根据输入样本对应的标签来计算损失值,最终反向传播优化参数。但是由于词汇量的庞大,导致要分类的基数也会非常巨大,这会使得最后一层要有海量的节点来对应词汇的个数(如上亿的词汇量),并且还要对其逐个计算概率值,判断其是该词汇的可能性。这种做法会使训练过程变得非常缓慢,进而无法完成任务。
为了解决这个问题,可使用一种候选采样的技巧,每次只评估所有类别的一个很小的子集,让网络的最后一层只在这个子集中做每个类别的评估计算。因为是监督学习,所以能够知道对应的正确标签(即正样本),额外挑选的子集(对应标签为0)被称为负样本。这样来训练网络,可在保证效率的同时同样会有很好的效果。
4、词向量的应用
在自然语言处理中,一般都会将该任务中涉及的词训练成词向量。然后让每个词以词向量的形式作为神经网络模型的输入,进行一些指定任务的训练。对于一个完整的训练任务,词向量的训练更多的情况是发生在预训练环节。词向量也可以理解成为onehot的升级版特征映射。从这个角度来看,只要样本序列彼此间有着某种联系,即使不是词,也可以用这种方法处理。例如,在做恶意域名分析检测任务中,可以把某一个域名字符当作一个词,进行词向量的训练。然后再将每个字符用训练好的一组特定的向量进行映射,作为后面模型真实的输入。这样的输入就会比单纯的onehot编码映射效果好很多。
word2vec
word2vec是谷歌提出的一种词嵌入的工具或者算法集合,采用了两种模型(CBOW与Skip-Gram模型)与两种方法(负采样与层次softmax方法)的组合,比较常见的组合为Skip-Gram和负采样方法。因为其速度快、效果好而广为人知,在任何场合可直接使用。
CBOW模型(Continous Bag of Words Model,CBOW)和Skip-Gram模型都是可以训练出词向量的方法,在具体代码操作中可以只选择其一,但CBOW要比Skip-Gram更快一些。
1、CBOW & Skip-Gram
前文说过统计语言模型就是给出几个词,在这几个词出现的前提下计算某个词出现的概率(事后概率)。
CBOW也是统计语言模型的一种,顾名思义就是根据某个词前面的n个词或者前后n个连续的词,来计算某个词出现的概率。Skip-Gram模型与之相反,是根据某个词,然后分别计算它前后出现某几个词的各个概率。
如例,“我爱人工智能”对于CBOW模型来讲,首先会将所有的字转成one_hot,然后取出其中的一个字当作输入,将其前面和后面的字分别当作标签,拆分成如下样子:
“我” “爱”
“爱” “我”
“爱” “人”
“人” “爱”
“人” “工”
每一行代表一个样本,第一列代表输入,第二列代表标签。将输入数据送进神经网络(如“我”),同时将输出的预测值与标签(“爱”)计算loss(如输入“我”对应的标签为“爱”,模型的预测输出值为“好”,则计算“爱”和“好”之间的损失偏差,用来优化网络),进行迭代优化,在整个词库中如果字数特别多,会产生很大的矩阵,影响softmax速度。word2vec使用基于Huffman编码的Hierarchical softmax筛选掉了一部分不可能的词,然后又用nagetive samping再去掉了一些负样本的词,所以时间复杂度就从O(V)变成了O(logV)。
2、TensorFlow的word2vec
在TensorFlow中提供了几个候选采样函数,用来处理loss计算中候选采样的工作,它们按不同的采样规则被封装成了不同的函数,说明如下。
tf.nn.uniform_candidate_sampler: 均匀地采样出类别子集。tf.nn.log_uniform_candidate_sampler:按照log-uniform (Zipfian)分布采样。zipfian叫齐夫分布,指只有少数词经常被使用,大部分词很少被使用。tf.nn.learned_unigram_candidate_sampler:按照训练数据中出现的类别分布进行采样。tf.nn.fixed_unigram_candidate_sampler:按照用户提供的概率分布进行采样。
在实际使用中一般先通过统计或者其他渠道知道待处理的类别满足哪些分布,接着就可以指定函数(或是在nn.fixed_unigram_candidate_sampler中指定对应的分布)来进行候选采样。如果实在不知道类别分布,还可以用tf.nn.learned_unigram_candidate_sampler。
learned_unigram_candidate_sampler的做法是先初始化一个[0,range_max]的数组,数组元素初始为1,在训练过程中碰到一个类别,就将相应数组元素加1,每次按照数组归一化得到的概率进行采样来实现的。
注意: 在语言相关的任务中,词按照出现频率从大到小排序之后,服从Zipfian分布。一般会先对类别按照出现频率从大到小排序,然后使用loguniform_candidate sampler函数。
TensorFlow的word2vec实现里,比对目标样本的损失值、计算softmax、负采样等过程统统封装到了nce_loss函数中,其默认使用的是log_uniform_candidate_sampler采样函数,在不指定特殊的采样器时,在该函数实现中会把词频越大的词,其类别编号也定义得越大,即优先采用词频高的词作为负样本,词频越高越有可能成为负样本。nce_loss函数配合优化器可以对最后一层的权重进行调优,更重要的是其还会以同样的方式调节word embedding(词嵌入)中的向量,让它们具有更合理的空间关系。
下面先来看看nce_loss函数的定义:
def nce_loss(weights, biases, inputs, labels, num_sampled, num_classes,
num_true=1,
sampled_values=None,
remove_accidental_hits=False,
partition_strategy="mod",
name="nce_loss")
假设输入数据是K维的,一共有N个类,其参数说明如下。
- weight:shape为(N,K)的权重。
- biases:shape为(N)的偏执。
- inputs:输入数据,shape为(batch_size,K)。
- labels:标签数据,shape为(batch_size,num_true)。
- num_true:实际的正样本个数。
- num_sampled:采样出多少个负样本。
- num_classes:类的个数N。
- sampled_values:采样出的负样本,如果是None,就会用默认的sampler去采样,优先采用词频高的词作为负样本。
- remove_accidental_hits:如果采样时采样到的负样本刚好是正样本,是否要去掉。
- partition_strategy:对weights进行embedding_lookup时并行查表时的策略。
TensorFlow的embeding_lookup是在CPU里实现的,这里需要考虑多线程查表时的锁的问题。
注意: 在TensorFlow中还有一个类似于nce_loss的函数sampled_softmax_loss,其用法与nce_loss函数完全一样。不同的是内部实现,nce_loss函数可以进行多标签分类问题,即标签之前不互斥,原因在于其对每一个输出的类都连接一个logistic二分类。而sampled_softmax_loss只能对单个标签分类,即输出的类别是互斥的,原因是其对每个类的输出放在一起统一做了一个多分类操作。


