损失函数
用真实值与预测值的距离来指导模型的收敛方向
损失函数是绝对网络学习质量的关键。在学到后面章节就会发现,无论什么样的网络结构,如果使用的损失函数不正确,最终都将难以训练出正确的模型。这里先介绍几个常见的loss函数,针对不同的网络结构还会有更多的loss函数,在后面章节会伴随不同的网络模型来介绍。
损失函数介绍
损失函数的作用前面已经说过了,用于描述模型预测值与真实值的差距大小。一般有两种比较常见的算法——均值平方差(MSE)和交叉熵。下面来分别介绍每个算法的具体内容。
均值平方差
均值平方差(Mean Squared Error,MSE),也称“均方误差”,在神经网络中主要是表达预测值与真实值之间的差异,在数理统计中,均方误差是指参数估计值与参数真值之差平方的期望值。公式定义如下,主要是对每一个真实值与预测值相减的平方取平均值:
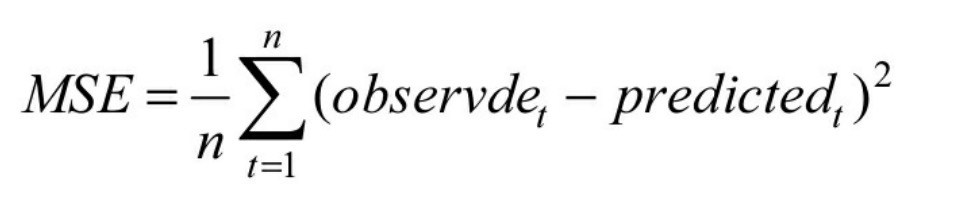
均方误差的值越小,表明模型越好。类似的损失算法还有均方根误差RMSE(将MSE开平方)、平均绝对值误差MAD(对一个真实值与预测值相减的绝对值取平均值)等。
注意: 在神经网络计算时,预测值要与真实值控制在同样的数据分布内,假设将预测值经过Sigmoid激活函数得到取值范围在0~1之间,那么真实值也归一化成0~1之间。这样在做loss计算时才会有较好的效果。
交叉熵
交叉熵(crossentropy)也是loss算法的一种,一般用在分类问题上,表达的意识为预测输入样本属于某一类的概率 。其表达式如下,其中y代表真实值分类(0或1),a代表预测值。
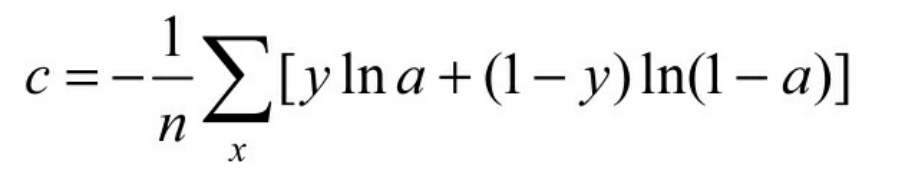
交叉熵也是值越小,代表预测结果越准。
注意: 这里用于计算的a也是通过分布统一化处理的(或者是经过Sigmoid函数激活的),取值范围在0~1之间。如果真实值和预测值都是1,前面一项yln(a)就是1ln(1)等于0,后一项(1-y)ln(1-a)也就是0ln(0)等于0,loss为0,反之loss函数为其他数。
总结:损失算法的选取
损失函数的选取取决于输入标签数据的类型:
- 如果输入的是实数、无界的值,损失函数使用平方差;
- 如果输入标签是位矢量(分类标志),使用交叉熵会更适合。
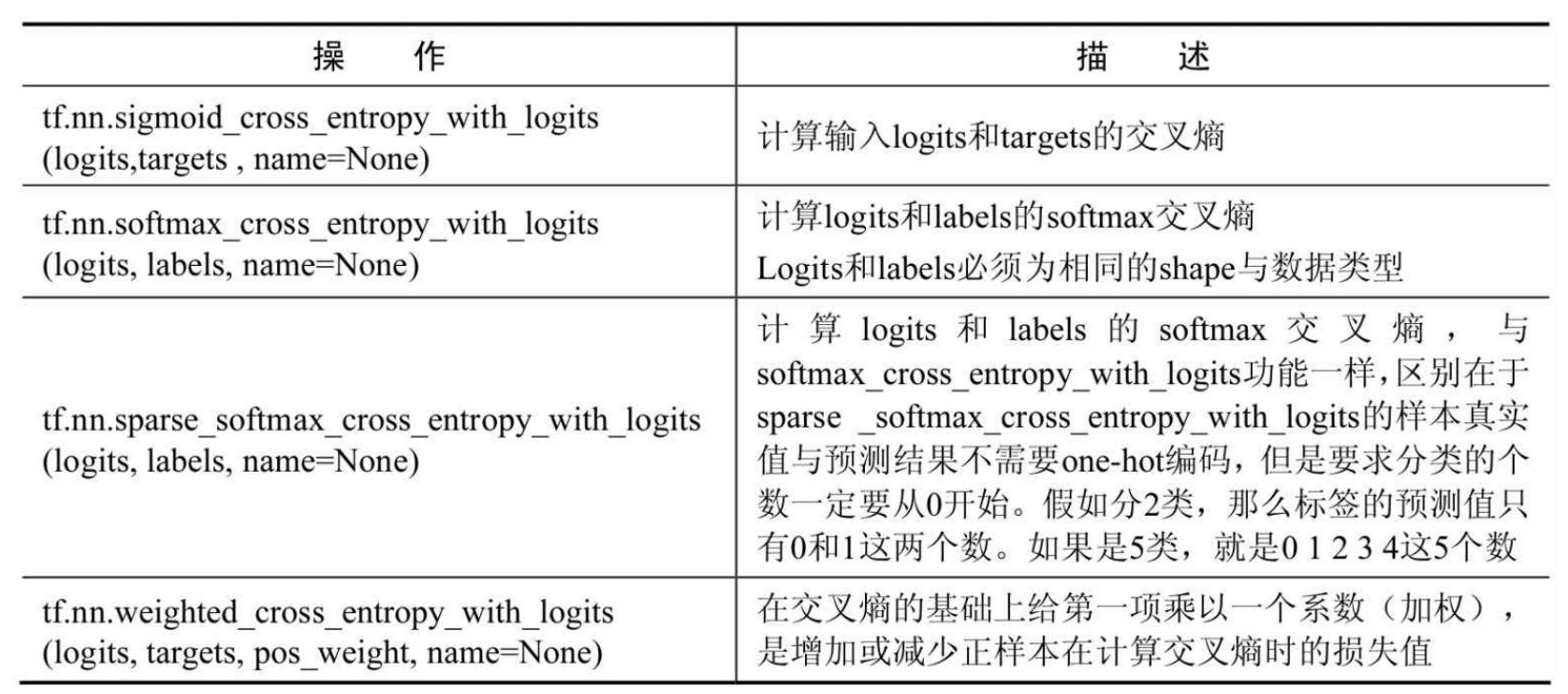
TensorFlow中常见的loss函数
下面看看TensorFlow中都有哪些常见的loss函数。
1.均值平方差
在TensorFlow没有单独的MSE函数,不过由于公式比较简单,往往开发者都会自己组合,而且也可以写出n种写法,例如:
MSE=tf.reduce_mean(tf.pow(tf.sub(logits, outputs), 2.0))
MSE=tf.reduce_mean(tf.square(tf.sub(logits, outputs)))
MSE=tf.reduce_mean(tf.square(logits- outputs))
- 代码中logits代表
标签值,outputs代表预测值。
同样也可以组合其他类似loss,例如:
Rmse= tf.sqrt(tf.reduce_mean(tf.pow(tf.sub(logits, outputs), 2.0)))
mad= tf.reduce_mean (tf.complex_abs(tf.sub(logits, outputs))
2.交叉熵
在TensorFlow中常见的交叉熵函数有:
- Sigmoid交叉熵;
- softmax交叉熵;
- Sparse交叉熵;
- 加权Sigmoid交叉熵。
图:在TensorFlow里常用的损失函数如表所示。
当然,也可以像MSE那样使用自己组合的公式计算交叉熵,举例,对于softmax后的结果logits我们可以对其使用公式-tf.reduce_sum(labels*tf.log(logits),1),就等同于softmax_cross_entropy_with_logits得到的结果。
softmax算法与损失函数的综合应用
在神经网络中使用softmax计算loss时对于初学者常常会犯很多错误,下面通过具体的实例代码来演示需要注意的关键地方与具体的用法。
实例:交叉熵实验
交叉熵这个比较生僻的术语,在深度学习领域中却是最常见的。由于其常用性,在TensorFlow中会被封装成多个版本,有的公式里直接带了交叉熵,有的需要自己单独求出,而在构建模型时,如果读者对这块知识不扎实,出现问题时会很难分析是模型的问题还是交叉熵的使用问题。因此这里有必要通过几个小实例将其弄得更明白一些。
实例描述
下面一段代码,假设有一个标签labels和一个网络输出值logits。这个实例就是以这两个值来进行以下3次实验。
- 两次softmax实验:将输出值logits分别进行1次和2次softmax,观察两次的区别及意义。
- 观察交叉熵:将步骤(1)中的两个值分别进行
softmax_cross_entropy_with_logits,观察它们的区别。 - 自建公式实验:将做两次softmax的值放到自建组合的公式里得到正确的值。
import tensorflow as tf
labels = [[0, 0, 1], [0, 1, 0]]
logits = [[2, 0.5, 6], [0.1, 0, 3]]
logits_scaled = tf.nn.softmax(logits)
logits_scaled2 = tf.nn.softmax(logits_scaled)
result1 = tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits)
result2 = tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits_scaled)
result3 = -tf.reduce_sum(labels * tf.log(logits_scaled), 1)
with tf.Session() as sess:
print("scaled=", sess.run(logits_scaled))
print("scaled2=", sess.run(logits_scaled2))
# 经过第二次的softmax后,分布概率会有变化
print("rel1=", sess.run(result1), "\n") # 正确的方式
print("rel2=", sess.run(result2), "\n")
# 如果将softmax变换完的值放进去会,就相当于算第二次softmax的loss,所以会出错
print("rel3=", sess.run(result3))
运行上面代码,输出结果如下:
scaled= [[ 0.01791432 0.00399722 0.97808844]
[ 0.04980332 0.04506391 0.90513283]]
scaled2= [[ 0.21747023 0.21446465 0.56806517]
[ 0.2300214 0.22893383 0.54104471]]
rel1= [ 0.02215516 3.09967351]
rel2= [ 0.56551915 1.47432232]
rel3= [ 0.02215518 3.09967351]
可以看到:logits里面的值原本加和都是大于1的,但是经过softmax之后,总和变成了1。样本中第一个是跟标签分类相符的,第二与标签分类不符,所以第一个的交叉熵比较小,是0.02215516,而第二个比较大,是3.09967351。
下面开始验证下前面所说的实验:
比较scaled和scaled2可以看到:经过第二次的softmax后,分布概率会有变化,而scaled才是我们真实转化的softmax值。
比较rel1和rel2可以看到:传入softmax_cross_entropy_with_logits的logits是不需要进行softmax的。如果将softmax后的值scaled传入softmax_cross_entropy_with_logits就相当于进行了两次的softmax转换。
对于已经用softmax转换过的scaled,在计算loss时就不能在用TensorFlow里面的softmax_cross_entropy_with_logits了。读者可以自己写一个loss函数,参见rel3的生成,通过自己组合的函数实现了softmax_cross_entropy_with_logits一样的结果。
one_hot实验
输入的标签也可以不是标准的one-hot。下面用一组总和也是1但是数组中每个值都不等于0或1的数组来代替标签,看看效果。
实例描述
对非one-hot编码为标签的数据进行交叉熵的计算,比较其与one-hot编码的交叉熵之间的差别。
接上述代码,将标签换为[[0.4,0.1,0.5],[0.3,0.6,0.1]]与原始的[[0,0,1],[0,1,0]]代表的分类意义等价,将这个标签代入交叉熵。
import tensorflow as tf
labels = [[0.4, 0.1, 0.5], [0.3, 0.6, 0.1]]
logits = [[2, 0.5, 6], [0.1, 0, 3]]
result4 = tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits)
with tf.Session() as sess:
print("rel4=", sess.run(result4), "\n")
运行上面的代码,生成结果如下:
rel4= [ 2.17215538 2.76967359]
比较前面的rel1发现,对于正确分类的交叉熵和错误分类的交叉熵,二者的结果差别没有标准one-hot那么明显。
实例:sparse交叉熵的使用
下面再举个例子看一下sparse_softmax_cross_entropy_with_logits函数的用法,它需要使用非one-hot的标签,所以,要把前面的标签换成具体数值[2,1],具体代码如下。
使用sparse_softmax_cross_entropy_with_logits函数,对非one-hot的标签进行交叉熵计算,比较其与one-hot标签在使用上的区别。
import tensorflow as tf
labels = [2, 1] # 表明labels中总共分为3个类: 0 、1、 2。[2,1]等价于onehot编码中的001与010
logits = [[2, 0.5, 6], [0.1, 0, 3]]
result5 = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=logits)
with tf.Session() as sess:
print("rel5=", sess.run(result5), "\n")
运行代码,生成结果如下:
rel5= [ 0.02215516 3.09967351]
发现rel5与前面的rel1结果完全一样。
实例:计算loss值
在真正的神经网络中,得到代码中的一个数组并不能满足要求,还需要对其求均值,使其最终变成一个具体的数值。
import tensorflow as tf
labels = [[0, 0, 1], [0, 1, 0]]
logits = [[2, 0.5, 6], [0.1, 0, 3]]
result1 = tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits)
loss = tf.reduce_sum(result1)
with tf.Session() as sess:
print("loss=", sess.run(loss))
运行上面的代码,生成结果如下:
loss= 3.1218286
演示通过分别对前面交叉熵结果result1与softmax后的结果logits_scaled计算loss,验证如下结论:
- 对于softmax_cross_entropy_with_logits后的结果求loss直接取均值。
- 对于softmax后的结果使用-tf.reduce_sum(labels * tf.log(logits_scaled))求loss。
- 对于softmax后的结果使用
-tf.reduce_sum(labels*tf.log(logits_scaled),1)等同于softmax_cross_entropy_with_logits结果。 - 由(1)和(3)可以推出对(3)进行求均值也可以得出正确的loss值,合并起来的公式为:
tf.reduce_sum(-tf.reduce_sum(labels*tf.log(logits_scaled),1))=loss
这便是我们最终要得到的损失值了。而对于rel3这种已经求得softmax的情况求loss,可以把公式进一步简化成:
loss2 = -tf.reduce_sum(labels * tf.log(logits_scaled))
接着添加示例代码。
import tensorflow as tf
labels = [[0, 0, 1], [0, 1, 0]]
logits = [[2, 0.5, 6], [0.1, 0, 3]]
result1 = tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits)
loss = tf.reduce_sum(result1)
with tf.Session() as sess:
print("loss=", sess.run(loss))
运行上面代码,输出结果如下:
loss2= 3.12183
与loss的值完全吻合。


