本节就来介绍一下这个基于注意力的Seq2Seq网络。
一、attention_seq2seq介绍
注意力机制,即在生成每个词时,对不同的输入词给予不同的关注权重。如图所示,右侧序列是输入序列,上方序列是输出序列。在注意力机制下,对于一个输出网络会自动学习与其对应的输入关系的权重。如How下面一列。
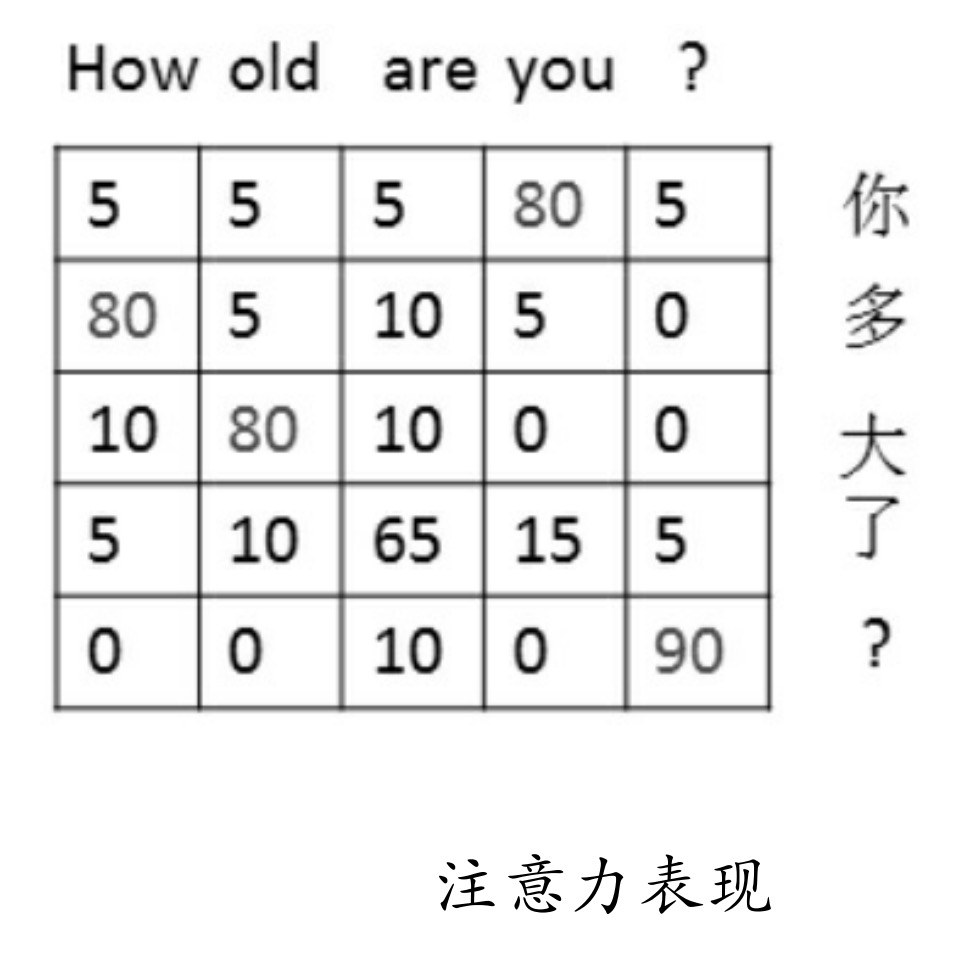
在训练过程中,模型会通过注意力机制把某个输出对应的所有输入列出来,学习其关系并更新到权重上。如图所示,“you”下面那一列(80、5、0、15、0),就是模型在生成you这个词时的概率分布,对应列的表格中值最大的地方对应的是输入的“你”(对应图中第1行第4列,值为80),说明模型在生成you这个词时最为关注的输入词是“你”。这样在预测时,该机制就会根据输入及其权重反向推出更有可能的预测值了。
注意力机制是在原有Seq2Seq中的Encoder与Decoder框架中修改而来,具体结构如图9-32所示。
修改后的模型特点是序列中每个时刻Encoder生成的c,都将要参与Decoder中解码的各个时刻,而不是只参与初始时刻。当然对于生成的结果节点c,参与到Decoder的每个序列运算都会经过权重w,那么这个w就可以以loss的方式通过优化器来调节了,最终会逐渐逼近与它紧密的那个词,这就是注意力的原理。添加入了Attention注意力分配机制后,使得Decoder在生成新的TargetSequence时,能得到之前Encoder编码阶段每个字符的隐藏层的信息向量Hidden State,使得新生成序列的准确度提高。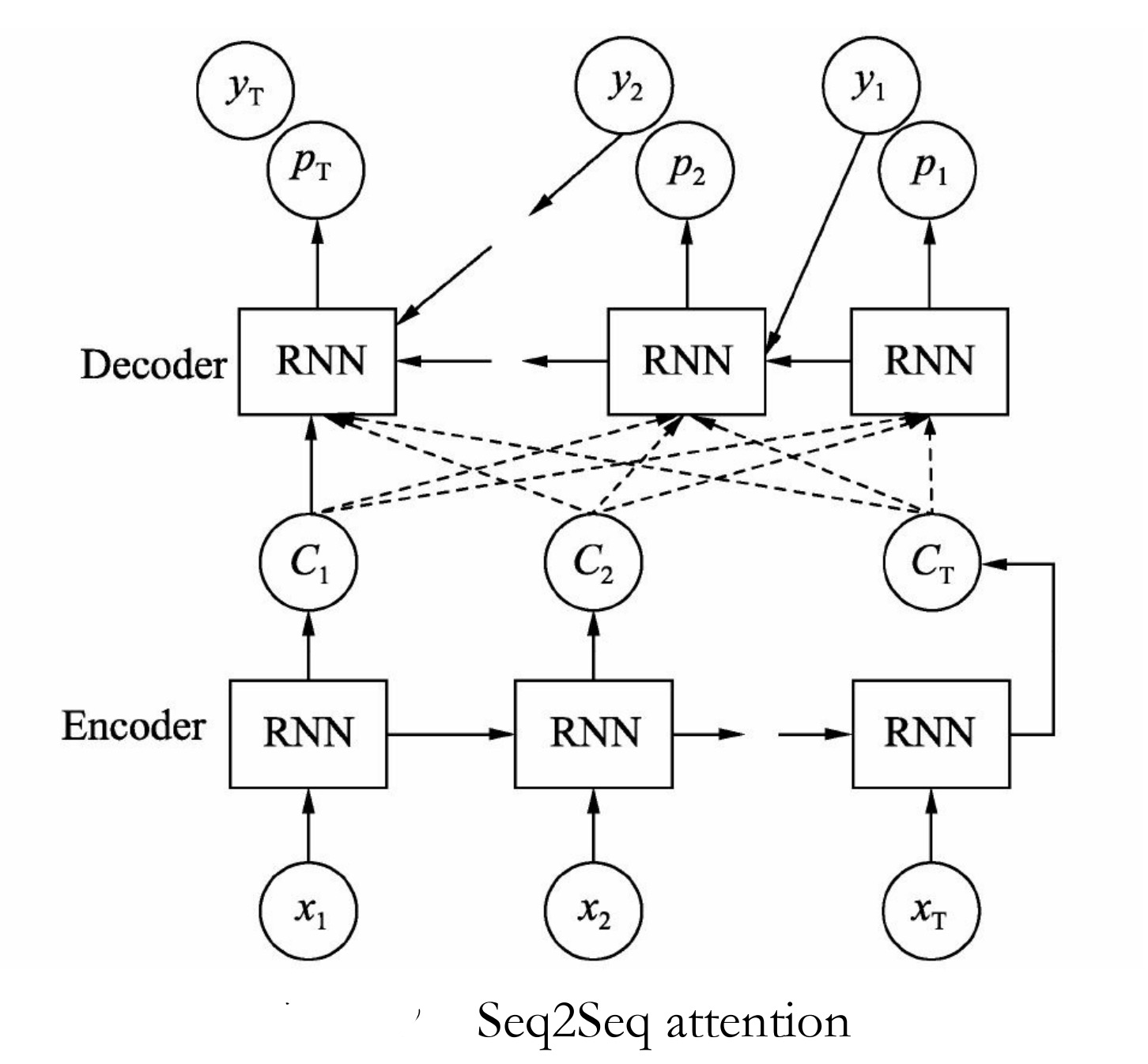
二、TensorFlow中的attention_seq2seq
在TensorFlow中也有关于带有注意力机制的Seq2Seq定义,封装后的Seq2Seq与前面basic_rnn_seq2seq差不多,具体函数如下:
tf.contrib.legacy_seq2seq.embedding_attention_seq2seq (encoder_inputs,
decoder_inputs,
cell,
num_encoder_symbols,
num_decoder_symbols,
embedding_size,
num_heads=1,
output_projection=None,
feed_previous=False,
dtype=None,
scope=None,
initial_state_attention=False):
参数说明如下。
- encoder_inputs:一个形状为[batch_size]的list。
- decoder_inputs:同encoder_inputs。
- cell:定义的cell网络。
- num_encoder_symbols:输入数据对应的词总个数。
- num_decoder_symbols:输出数据对应的词的总个数。
- embedding_size:每个输入对应的词向量编码大小。
- num_heads:从注意力状态里读取的个数。
- output_projection:对输出结果是否进行全连接的维度转化,如果需要转化,则传入全连接对应的w和b。
- feed_previous:为True时,表明只有第一个Decoder输入以Go开始,其他都使用前面的状态。如果为False时,每个Decoder的输入都会以Go开始。Go为自己定义模型时定义的一个起始符,一般用0或1来指定。
三、Seq2Seq中桶(bucket)的实现机制
在Seq2Seq模型中,由于输入、输出都是可变长的,这就给计算带来了很大的效率影响。在TensorFlow中使用了一个“桶”(bucket)的观念来权衡这个问题,思想就是初始化几个bucket,对数据预处理,按照每个序列的长短,将其放到不同的bucket中,小于bucket size部分统一补0来完成对齐的工作,之后就可以进行不同bucket的批处理计算了。
由于该问题与Seq2Seq模型关联比较紧密,在TensorFlow中就将其封装成整体的框架模式,开发者只需要将输入、输出、网络模型传入函数中,其他的都交给函数自己来处理,大大简化了开发过程,其定义如下:
model_with_buckets(encoder_inputs,
decoder_inputs,
targets,
weights,
buckets,
seq2seq,
softmax_loss_function=None,
per_example_loss=False,
name=None):
参数说明如下。
- encoder_inputs:一个形状为[batch_size]的list。
- decoder_inputs:同encoder_inputs,作为解码器部分的输入。
- targets:最终输出结果的label。
- weights:传入的权重值,必须与decoder_inputs的size相同。
- buckets:传入的桶,描述为[(xx,xx),(xx,xx)…]每一对有两个数,第一个数为输入的size,第二个数为输出的size。
- seq2seq:带有Seq2Seq结构的网络,以函数名的方式传入。在Seq2Seq里可以载入定义的cell网络。
- softmax_loss_function:是否使用自己指定的loss函数。
- per_example_loss:是否对每个样本求loss。
这里面有疑问的部分就是weights,为什么会多了个weights?它是做什么的呢?跟进代码里可以看到,它会调用sequence_loss_by_example函数,在sequence_loss_by_example函数中weights是用来做loss计算的。具体见tensorflow\contrib\legacy_seq2seq\python\ops\seq2seq.py文件中第1048行函数sequence_loss_by_example的实现,代码如下:
……
with ops.name_scope(name, "sequence_loss_by_example",
logits + targets + weights):
log_perp_list = []
for logit, target, weight in zip(logits, targets, weights):
if softmax_loss_function is None:
# TODO(irving,ebrevdo):为了符合调用sequence_loss_by_example时的需要,需要对张量进行reshape
target = array_ops.reshape(target, [-1])
crossent = nn_ops.sparse_softmax_cross_entropy_with_logits(
labels=target, logits=logit)
else:
crossent = softmax_loss_function(labels=target, logits=logit)
log_perp_list.append(crossent * weight)
log_perps = math_ops.add_n(log_perp_list)
if average_across_timesteps:
total_size = math_ops.add_n(weights)
total_size += 1e-12 # 避免除数为0
log_perps /= total_size
return log_perps
可见在求每个样本loss时对softmax_loss的结果乘了weight,同时又将乘完weight后的总和结果除以weights的总和(log_perps /= total_size)。这种做法就是叫做基于权重的交叉熵计算(weighted cross_entropy loss)(具体细节不再展开,读者简单了解即可)。


