在上面的例子中仅仅迭代了20次就得到了一个可以拟合y≈2x的模型。下面来具体了解一下模型是如何得来的。
模型里的内容及意义
一个标准的模型结构分为输入、中间节点、输出三大部分,而如何让这三个部分连通起来学习规则并可以进行计算,则是框架TensorFlow所做的事情。
TensorFlow将中间节点及节点间的运算关系(OPS)定义在自己内部的一个“图”上,全通过一个“会话(session)”进行图中OPS的具体运算。
可以这样理解:
- “图”是静态的,无论做任何加、减、乘、除,它们只是将关系搭建在一起,不会有任何运算。
- “会话”是动态的,只有启动会话后才会将数据流向图中,并按照图中的关系运算,并将最终的结果从图中流出。
TensorFlow用这种方式分离了计算的定义和执行,“图”类似于施工图(blueprint),而“会话”更像施工地点。
构建一个完整的图一般需要定义3种变量,如图所示。
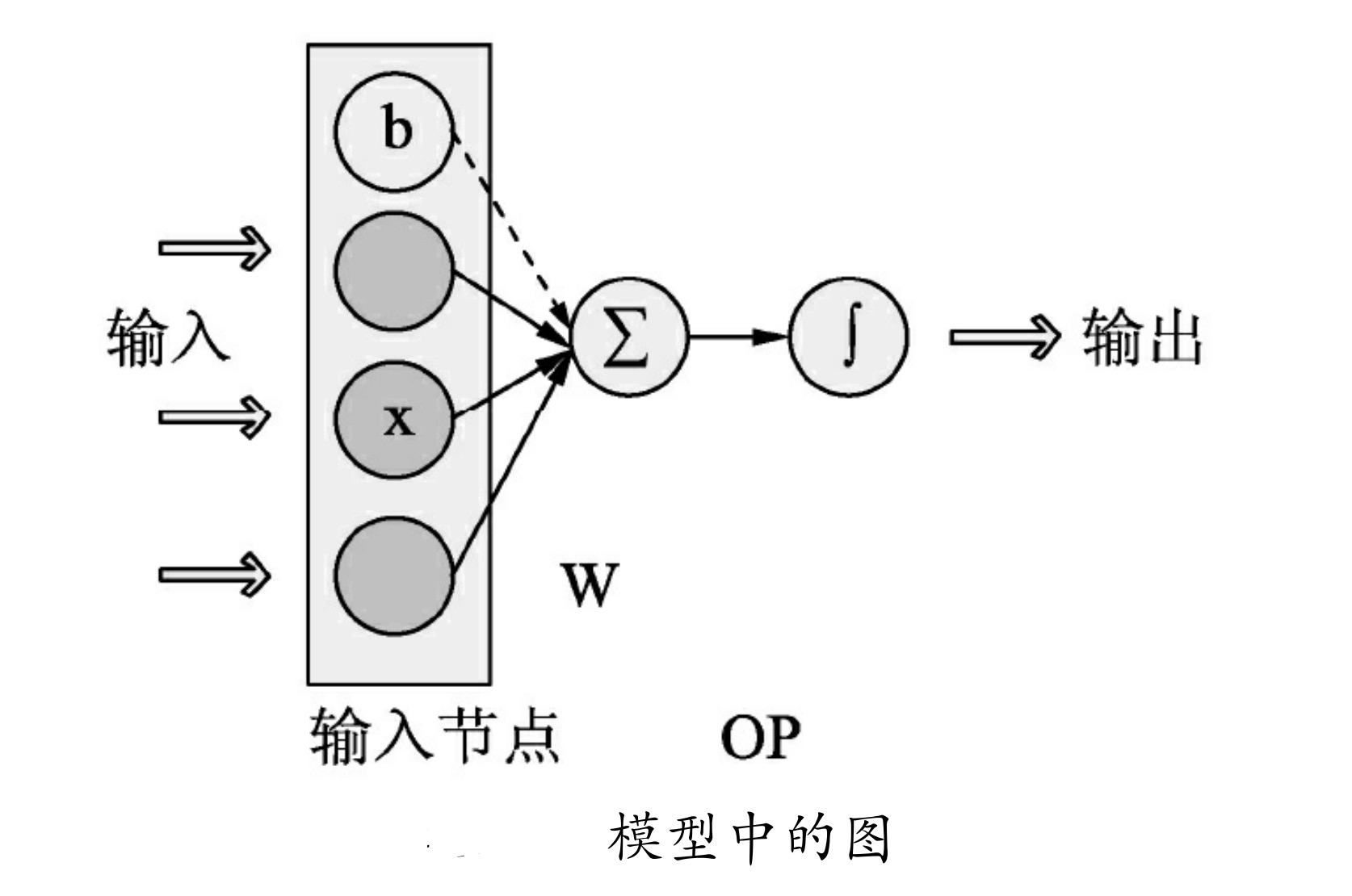
输入节点:即网络的入口。
用于训练的模型参数(也叫学习参数):是连接各个节点的路径。
模型中的节点(OP):最复杂的就是OP。OP可以用来代表模型中的中间节点,也可以代表最终的输出节点,是网络中的真正结构。
如图所示为这3种变量放在图中所组成的网络静态模型。在实际训练中,通过动态的会话将图中的各个节点按照静态的规则运算起来,每一次的迭代都会对图中的学习参数进行更新调整,通过一定次数的迭代运算之后最终所形成的图便是所要的“模型”。而在会话中,任何一个节点都可以通过会话的run函数进行计算,得到该节点的真实数值。
模型内部的数据流向
模型内部的数据流向分为正向和反向。
1.正向
正向,是数据从输入开始,依次进行各节点定义的运算,一直运算到输出,是模型最基本的数据流向。它直观地表现了网络模型的结构,在模型的训练、测试、使用的场景中都会用到。这部分是必须要掌握的。
2.反向
反向,只有在训练场景下才会用到。这里使用了一个叫做反向链式求导的方法,即先从正向的最后一个节点开始,计算此时结果值与真实值的误差,这样会形成一个用学习参数表示误差的方程,然后对方程中的每个参数求导,得到其梯度修正值,同时反推出上一层的误差,这样就将该层节点的误差按照正向的相反方向传到上一层,并接着计算上一层的修正值,如此反复下去一步一步地进行转播,直到传到正向的第一个节点。
这部分原理TensorFlow已经实现好了,您简单理解即可,应该把重点放在使用什么方法来计算误差,使用哪些梯度下降的优化方法,如何调节梯度下降中的参数(如学习率)问题上。
了解TensorFlow开发的基本步骤
通过上面的例子,现在将TensorFlow开发的基本步骤总结如下:
(1)定义TensorFlow输入节点。
(2)定义“学习参数”的变量。
(3)定义“运算”。
(4)优化函数,优化目标。
(5)初始化所有变量。
(6)迭代更新参数到最优解。
(7)测试模型。
(8)使用模型。
(1)定义输入节点的方法
TensorFlow中有如下几种定义输入节点的方法。
- 通过占位符定义:一般使用这种方式。
- 通过字典类型定义:一般用于输入比较多的情况。
- 直接定义:一般很少使用。
上篇文章的第一个例子“线性回归”就是通过占位符来定义输入节点的,具体使用了tf.placeholder函数,见如下代码。
X = tf.placeholder("float")
Y = tf.placeholder("float")
实例2:通过字典类型定义输入节点
使用字典占位符来代替用占位符定义的输入,通过字典定义的方式和第一种比较像,只不过是堆叠到了一起。具体代码如下:
……
# 占位符
inputdict = {
'x': tf.placeholder("float"),
'y': tf.placeholder("float")
}
实例3:直接定义输入节点
使用直接定义法来代替用占位符定义的输入。直接定义,就是将定义好的Python变量直接放到OP节点中参与输入的运算,将模拟数据的变量直接放到模型中进行训练。代码如下:
……
#生成模拟数据
train_X =np.float32(np.linspace(-1, 1, 100))
train_Y = 2 * train_X + np.random.randn(*train_X.shape) * 0.3 # y=2x,但是加入了噪声
#图形显示
plt.plot(train_X, train_Y, 'ro', label='Original data')
plt.legend()
plt.show()
# 模型参数
W = tf.Variable(tf.random_normal([1]), name="weight")
b = tf.Variable(tf.zeros([1]), name="bias")
# 前向结构
z = tf.multiply(W, train_X)+ b
(2)定义“学习参数”的变量
学习参数的定义与输入的定义很像,分为直接定义和字典定义两部分。这两种都是常见的使用方式,只不过在深层神经网络里由于参数过多,普遍都会使用第二种情况。
在前面“线性回归”的例子中使用的就是第一种方法,通过tf.Variable可以对参数直接定义。代码如下:
# 模型参数
W = tf.Variable(tf.random_normal([1]), name="weight")
b = tf.Variable(tf.zeros([1]), name="bias")
下面通过例子演示使用字典定义学习参数。
实例4:通过字典类型定义“学习参数”
在代码“线性回归.py”文件的基础上,使用字典的方式来定义学习参数。通过字典的方式定义和直接定义比较相似,只不过是堆叠到了一起。修改“线性回归.py”例子代码如下。
……
# 模型参数
paradict = {
'w': tf.Variable(tf.random_normal([1])),
'b': tf.Variable(tf.zeros([1]))
}
# 前向结构
z = tf.multiply(X, paradict['w']) + paradict['b']
(3)定义“运算”
定义“运算”的过程是建立模型的核心过程,直接决定了模型的拟合效果,具体的代码演示在前面也介绍过了。这里主要阐述一下定义运算的类型,以及其在深度学习中的作用。
1.定义正向传播模型
在前面“线性回归.py”的例子中使用的网络结构很简单,只有一个神经元。在后面会学到多层神经网络、卷积神经网、循环神经网络及更深层的GoogLeNet、Resnet等,它们都是由神经元以不同的组合方式组成的网络结构,而且每年还会有很多更高效且拟合性更强的新结构诞生。
2.定义损失函数
损失函数主要是计算“输出值”与“目标值”之间的误差,是配合反向传播使用的。为了在反向传播中可以找到最小值,要求该函数必须是可导的。
提示: 损失函数近几年来没有太大变化。读者只需要记住常用的几种,并能够了解内部原理就可以了,不需要掌握太多细节,因为TensorFlow框架已经为我们做好了。
(4)优化函数,优化目标
在有了正向结构和损失函数后,就是通过优化函数来优化学习参数了,这个过程也是在反向传播中完成的。
反向传播过程,就是沿着正向传播的结构向相反方向将误差传递过去。这里面涉及的技术比较多,如L1、L2正则化、冲量调节、学习率自适应、adm随机梯度下降算法等,每一个技巧都代表一个时代。
提示: 随着深度学习的飞速发展,反向传播过程的技术会达到一定程度的瓶颈,更新并不如网络结构变化得那么快,所以读者也只需将常用的几种记住即可。
(5)初始化所有变量
初始化所有变量的过程,虽然只有一句代码,但也是一个关键环节,所以特意将其列出来。
在session创建好了之后,第一件事就是需要初始化。还以“线性回归.py”举例,代码如下:
init = tf.global_variables_initializer()
# 启动Session
with tf.Session() as sess:
sess.run(init)
注意: 使用
tf.global_variables_initializer函数初始化所有变量的步骤,必须在所有变量和OP定义完成之后。这样才能保证定义的内容有效,否则,初始化之后定义的变量和OP都无法使用session中的run来进行算值。
(6)迭代更新参数到最优解
在迭代训练环节,都是需要通过建立一个session来完成的,常用的是使用with语法,可以在session结束后自行关闭,当然还有其他方法,后面会详细介绍。
with tf.Session() as sess:
前面说过,在session中通过run来运算模型中的节点,在训练环节也是如此,只不过run里面放的是优化操作的OP,同时会在外层加上循环次数。
for epoch in range(training_epochs):
for (x, y) in zip(train_X, train_Y):
sess.run(optimizer, feed_dict={X: x, Y: y})
真正使用过程中会引入一个叫做MINIBATCH概念进行迭代训练,即每次取一定量的数据同时放到网络里进行训练,这样做的好处和意义会在后面详细介绍。
(7)测试模型
测试模型部分已经不是神经网络的核心环节了,同归对评估节点的输出,得到模型的准确率(或错误率)从而来描述模型的好坏,这部分很简单没有太多的技术,在“线性回归.py”中可以找到如下代码:
print ("cost=", sess.run(cost, feed_dict={X: train_X, Y: train_Y}), "W=",sess.run(W), "b=", sess.run(b))
当然这句话还可以改写成以下这样:
print ("cost:",cost.eval({X: train_X, Y: train_Y}))
(8)使用模型
使用模型也与测试模型类似,只不过是将损失值的节点换成输出的节点即可。在“线性回归.py”例子中也有介绍。
这里要说的是,一般会把生成的模型保存起来,再通过载入已有的模型来进行实际的使用。关于模型的载入和读取,后面章节会有介绍。


