上面的章节中演示的代码看似功能很强大,但也仅限于简单的逻辑和样本。对于相对较复杂的问题,这种RNN便会显出其缺陷,原因还是出在激活函数。通常来讲,激活函数在神经网络里最多只能6层左右,因为它的反向误差传递会随着层数的增加,传递的误差值越来越小,而在RNN中,误差传递不仅存在于层与层之间,也在存于每一层的样本序列间,所以RNN无法去学习太长的序列特征。
于是,神经网络学科中又演化了许多RNN网络的变体版本,使得模型能够学习更长的序列特征。接下来一起看看循环神经网络RNN的各种演化版本及内部原理与结构。
LSTM网络介绍
长短记忆的时间递归神经网络(Long Short Term Memory,LSTM)可以算是RNN网络的代表,其结构同样也非常复杂,下面一起来学习一下。
整体介绍
LSTM是一种RNN特殊的类型,可以学习长期依赖信息。LSTM通过刻意的设计来避免长期依赖问题,其结构示意如图所示。
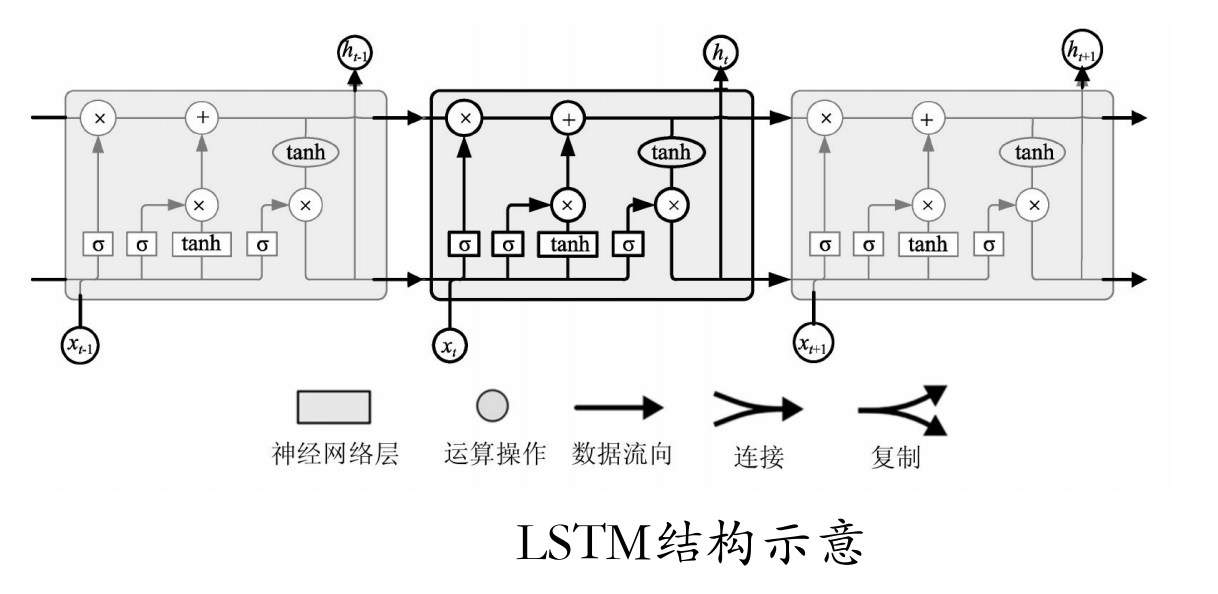
图中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。方框上方的圆圈代表运算操作(如向量的和),而中间的方框就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。
将其简化成图,就与之前所说的结构一样了(这里的激活函数使用的是Tanh)。
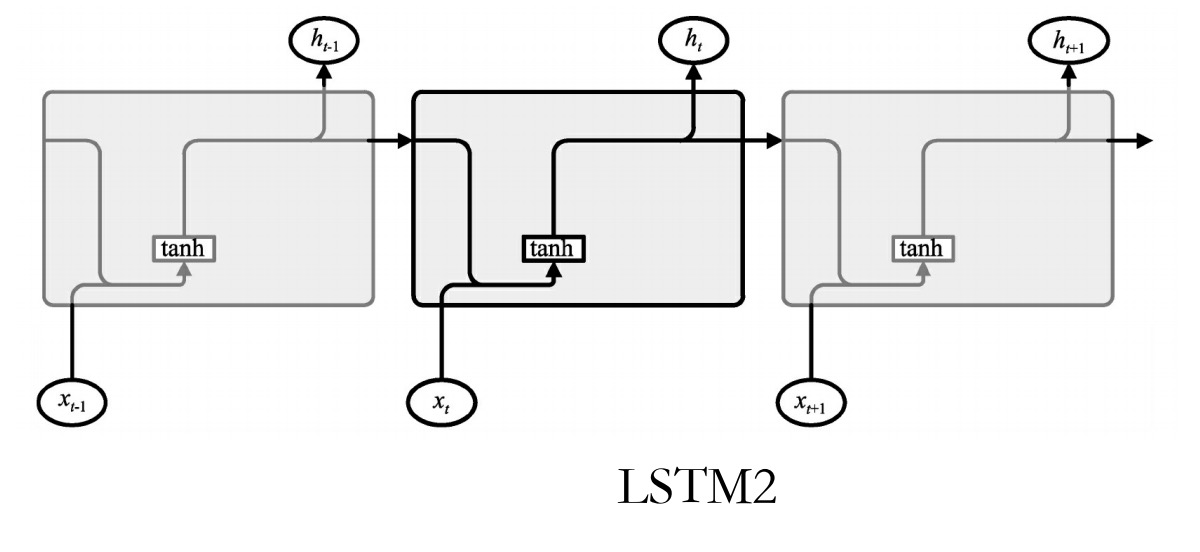
这种结构的核心思想是引入了一个叫做细胞状态的连接,这个细胞状态用来存放想要记忆的东西(对应于简单RNN中的h,只不过这里面不再只存放上一次的状态了,而是通过网络学习存放那些有用的状态)。同时在里面加入3个门。
- 忘记门:决定什么时候需要把以前的状态忘记。
- 输入门:决定什么时候加入新的状态。
- 输出门:决定什么时候需要把状态和输入放在一起输出。
从字面意思可以看出,简单RNN只是把上一次的状态当成本次的输入一起输出。而LSTM在状态的更新和状态是否参与输入都做了灵活的选择,具体选什么,则一起交给神经网络的训练机制来训练。
现在分别介绍一下这三个门的结构和作用。
2.忘记门
如图所示为忘记门。该门决定模型会从细胞状态中丢弃什么信息。
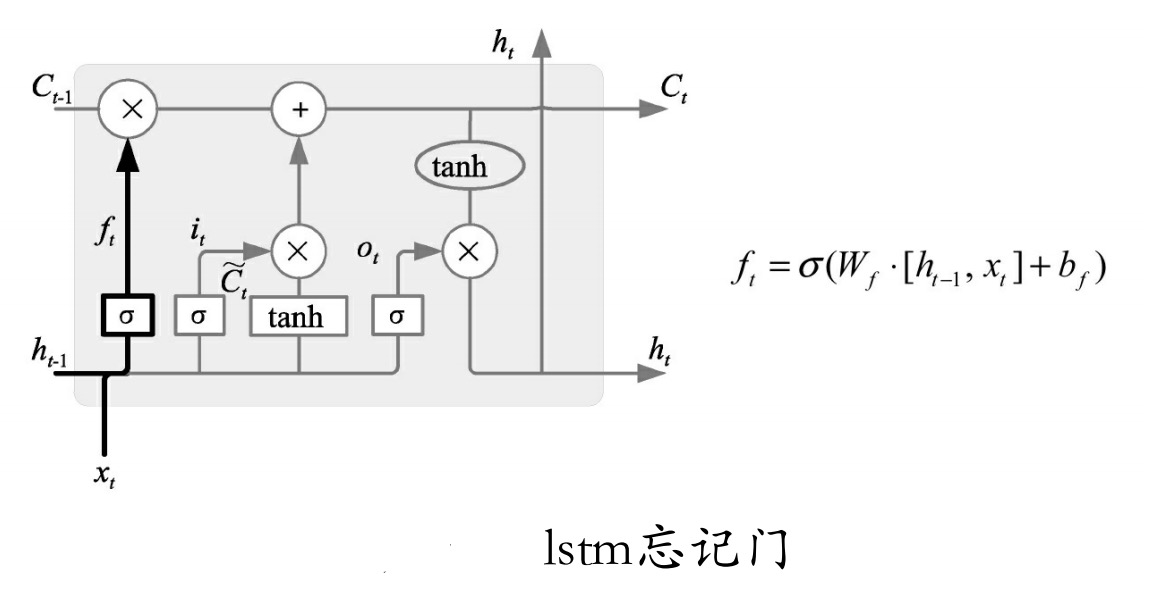
该门会读取ht-1 和xt ,输出一个在0~1之间的数值给每个在细胞状态Ct-1 中的数字。1表示“完全保留”,0表示“完全舍弃”。
例如一个语言模型的例子,假设细胞状态会包含当前主语的性别,于是根据这个状态便可以选择正确的代词。当我们看到新的主语时,应该把新的主语在记忆中更新。该门的功能就是先去记忆中找到以前那个旧的主语(并没有真正忘掉操作,只是找到而已)。
3.输入门
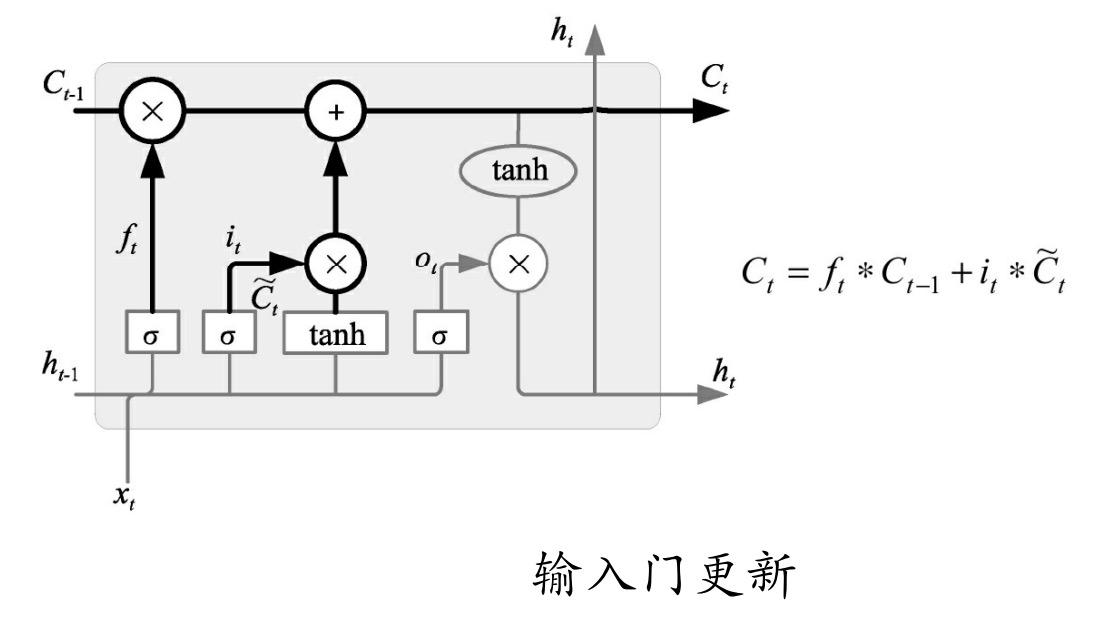
输入门其实可以分成两部分功能,如图所示。一部分是找到那些需要更新的细胞状态,另一部分是把需要更新的信息更新到细胞状态里。
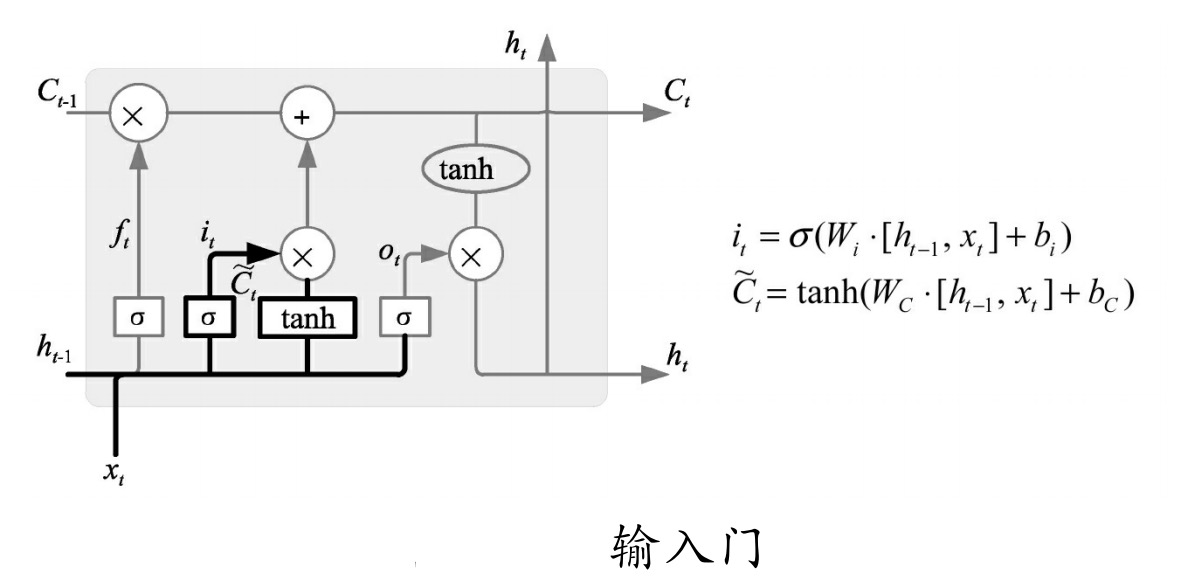
其中,tanh层就是要创建一个新的细胞状态值向量——Ct ,会被加入到状态中。
忘记门找到了需要忘掉的信息ft后,再将它与旧状态相乘,丢弃掉确定需要丢弃的信息。再将结果加上it × Ct使细胞状态获得新的信息,这样就完成了细胞状态的更新,如图所示。
4.输出门
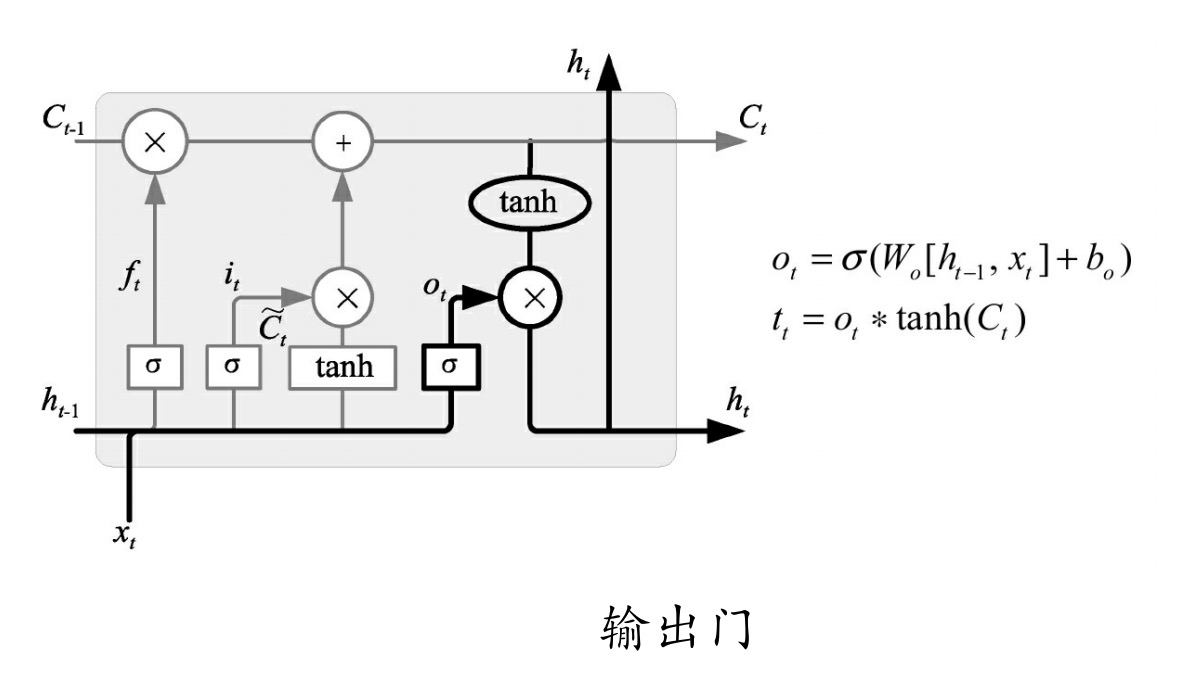
如图所示,在输出门中,通过一个Sigmoid层来确定哪部分的信息将输出,接着把细胞状态通过Tanh进行处理(得到一个在-1~1之间的值)并将它和Sigmoid门的输出相乘,得出最终想要输出的那部分,例如在语言模型中,假设已经输入了一个代词,便会计算出需要输出一个与动词相关的信息。
窥视孔连接(Peephole)
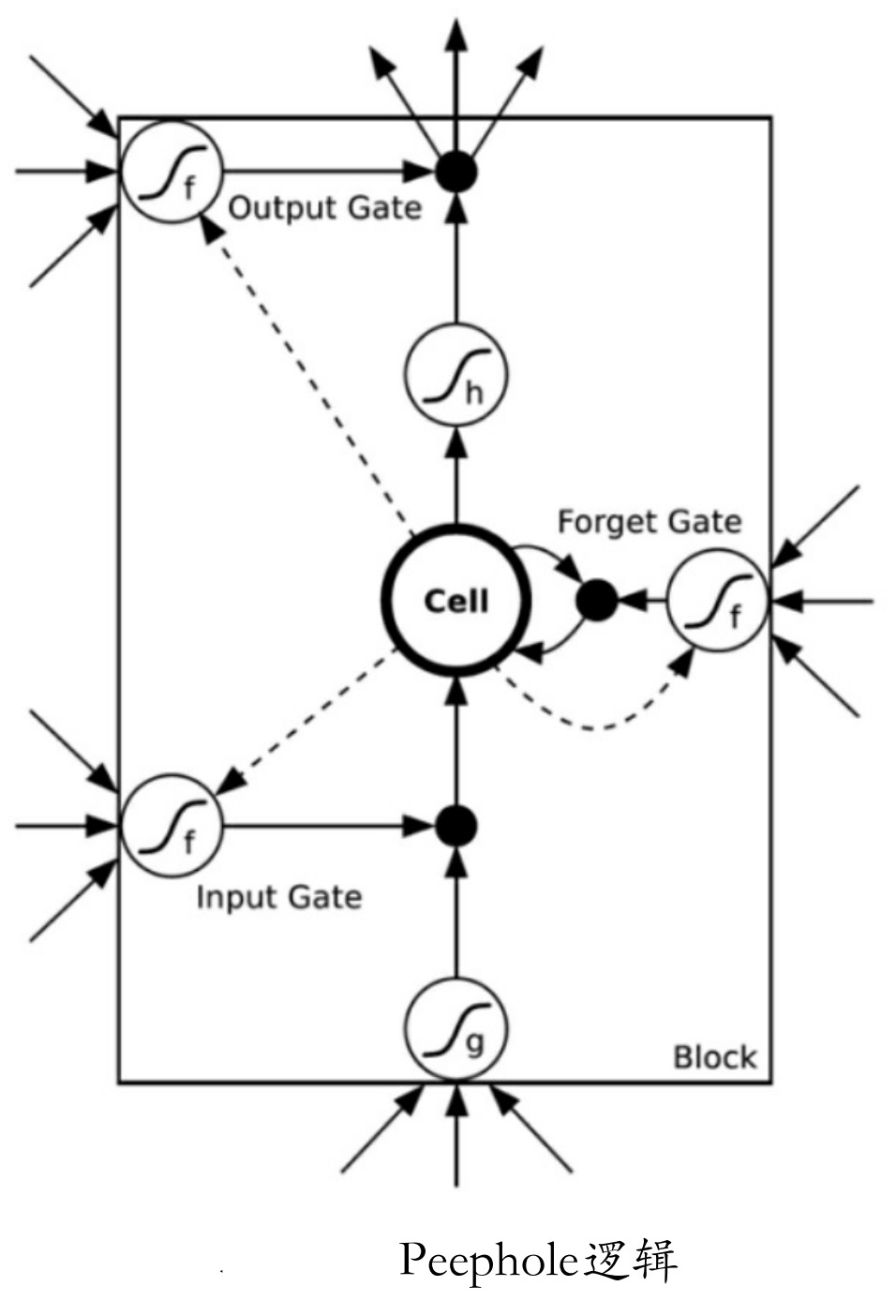
窥视孔连接(Peephole)的出现是为了弥补忘记门一个缺点:当前cell的状态不能影响到Input Gate,Forget Gate在下一时刻的输出,使整个cell对上个序列的处理丢失了部分信息。所以增加了Peephole connections,如图所示虚线部分。计算的顺序为:
(1)上一时刻从cell输出的数据,随着本次时刻的数据一起输入Input Gate和Forget Gate。
(2)将输入门和忘记门的输出数据同时输入cell中。
(3)cell出来的数据输入到当前时刻的 Output Gate,也输入到下一时刻的input gate,forget gate。
(4)Forget Gate输出的数据与cell激活后的数据一起作为整个Block的输出。
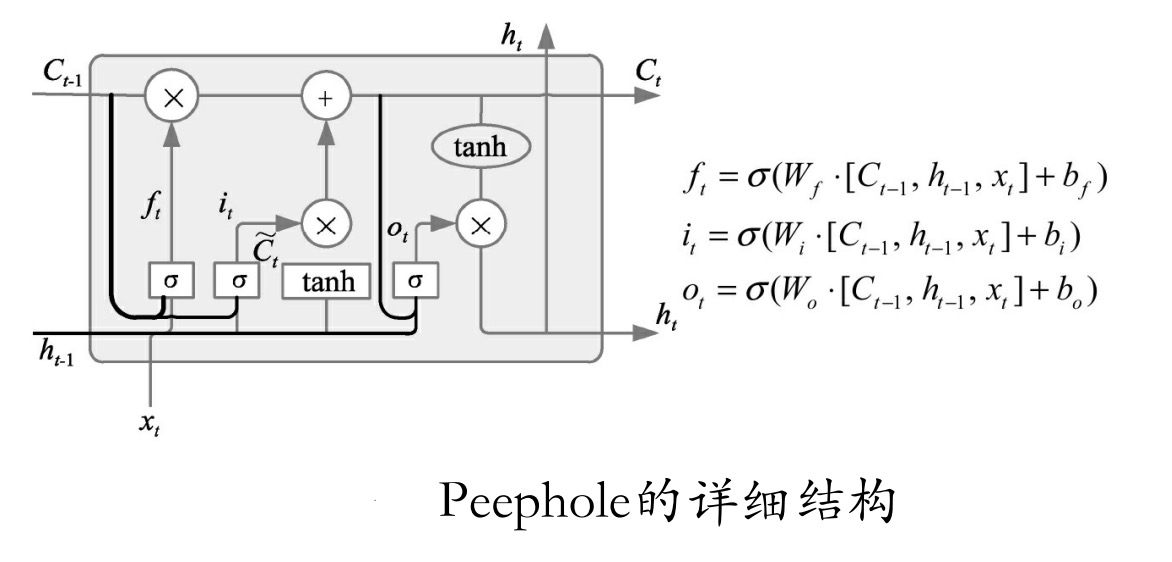
如图所示为Peephole的详细结构。通过这样的结构,将Gate的输入部分增加了一个来源 -- Forget Gate,Input Gate的输入来源增加了cell前一时刻的输出,Output Gate的输入来源增加了cell当前时刻的输出,使cell对序列记忆增强。
带有映射输出的STMP
带有映射的LSTM(lstm with recurrent projection layer),在原有lSTM基础之上增加了一个映射层(projection layer),并将这个layer连接到lSTM的输入,该映射层是通过全连接网络来实现的,可以通过改变其输出维度调节总的参数量,起到模型压缩的作用。
基于梯度剪辑的cell
基于梯度剪辑的cell(Clipping cell)源于这个问题:LSTM的损失函数是每一个时间点的RNN的输出和标签的交叉熵(cross-entropy)之和。这种loss在使用Backpropagation through time(BPTT)梯度下降法的训练过程中,可能会出现剧烈的抖动。
当参数值在较为平坦的区域更新时,由于该区域梯度值比较小,此时的学习率一般会变得较大,如果突然到达了陡峭的区域,梯度值陡增,再与此时较大的学习率相乘,参数就有很大幅度的更新,因此学习过程非常不稳定。
Clipping cell方法的使用可以优化这个问题,具体做法是:为梯度设置阈值,超过该阈值的梯度值都会被cut,这样参数更新的幅度就不会过大,因此容易收敛。
从原理上可以理解为:RNN和LSTM的记忆单元的相关运算是不同的,RNN中每一个时间点的记忆单元中的内容(隐藏层结点)都会更新,而LSTM则是使用忘记门机制将记忆单元中的值与输入值相加(按某种权值)再更新(cell状态),记忆单元中的值会始终对输出产生影响(除非Forget Gate完全关闭),因此梯度值易引起爆炸,所以Clipping功能是很有必要的。
GRU网络介绍
GRU是与LSTM功能几乎一样的另一个常用的网络结构,它将忘记门和输入门合成了一个单一的更新门,同样还混合了细胞状态和隐藏状态及其他一些改动。最终的模型比标准的LSTM模型要简单,如图所示。
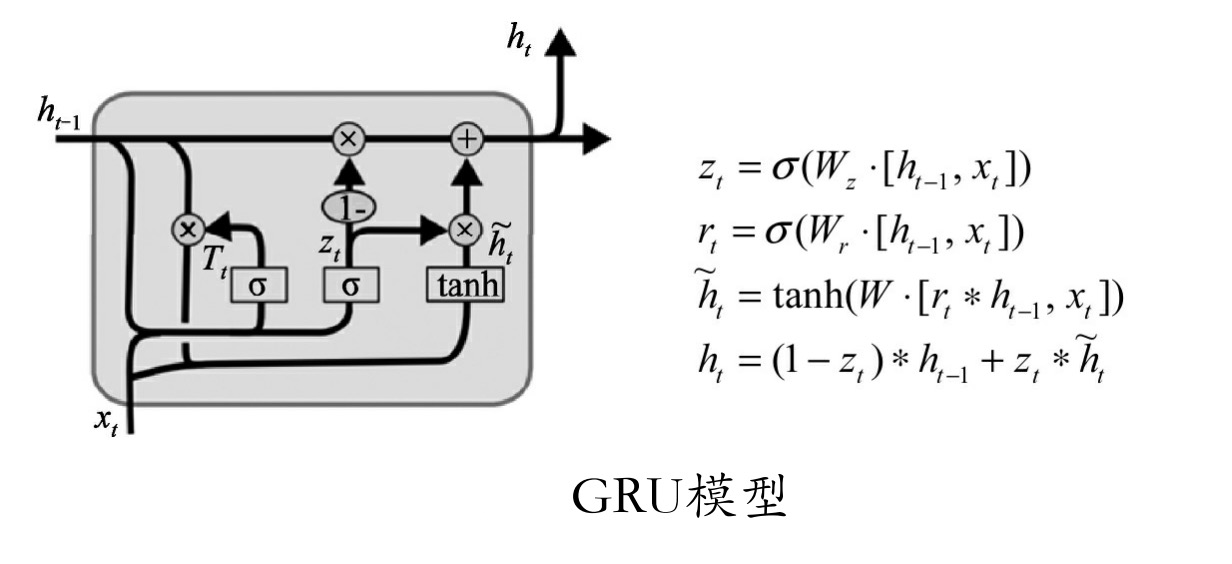
当然,基于LSTM的变体不止GRU一个,并且经过一些专业人士的测试,它们在性能和准确度上几乎没什么差别,只是在具体的某些业务上会有略微不同。
由于GRU比LSTM少一个状态输出,效果几乎一样,因此在编码时使用GRU可以让代码更为简单一些。
3.6 Bi-RNN网络介绍
Bi-RNN又叫双向RNN,是采用了两个方向的RNN网络。
RNN网络擅长的是对于连续数据的处理,既然是连续的数据规律,我们不仅可以学习它的正向规律,还可以学习它的反向规律。这样将正向和反向结合的网络,会比单向的循环网络有更高的拟合度。例如,预测一个语句中缺失的词语,则需要根据上下文来进行预测。
双向RNN的处理过程与单向的RNN非常类似,就是在正向传播的基础上再进行一次反向传播,而且这两个都连接着一个输出层。这个结构提供给输出层输入序列中,每一个点完整的过去和未来的上下文信息。图9-19所示为一个沿着时间展开的双向循环神经网络。
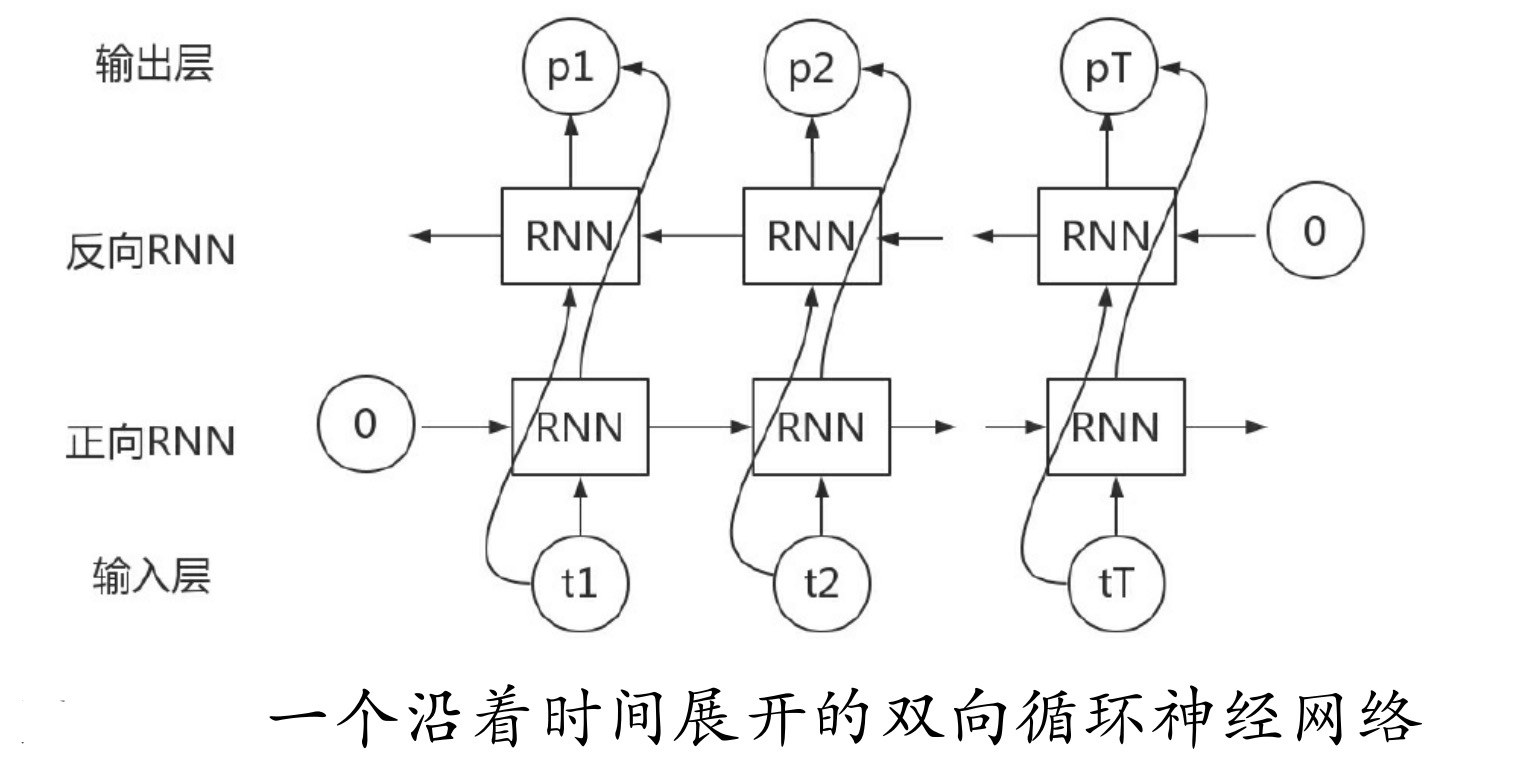
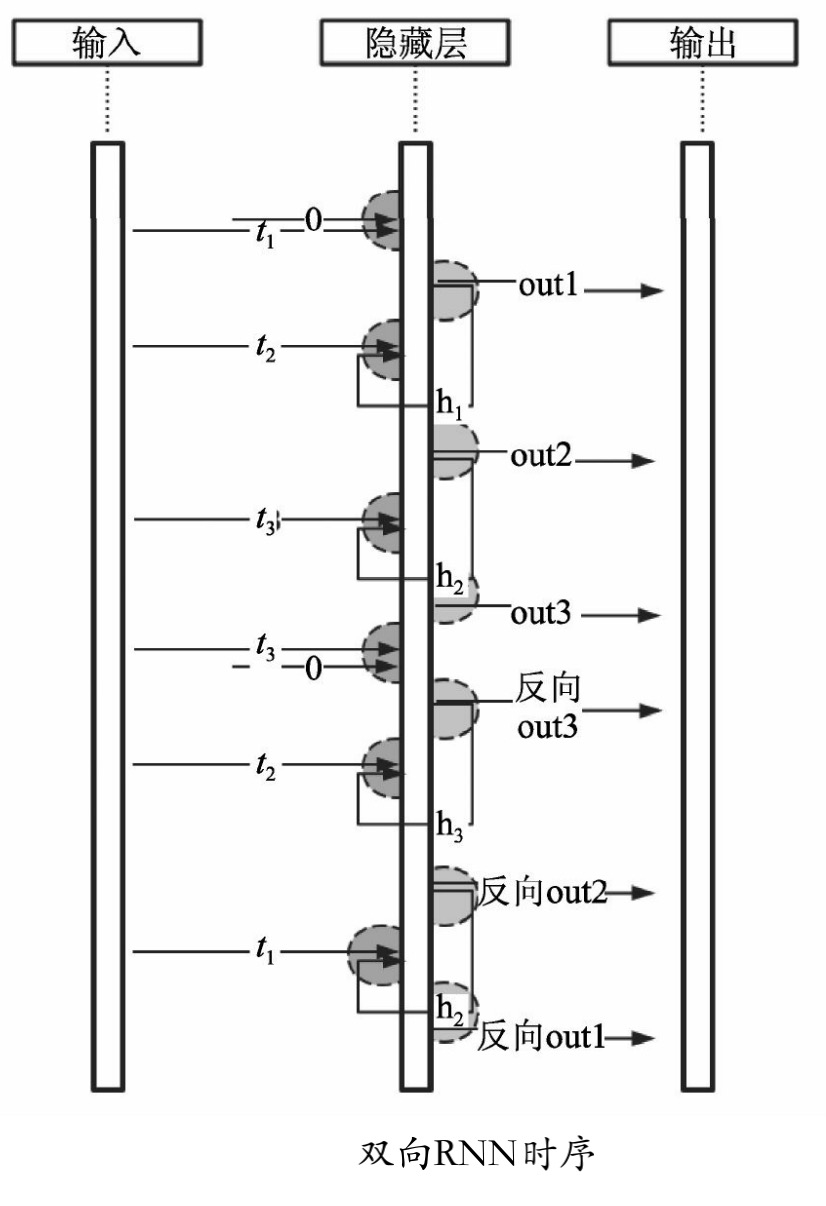
双向RNN会比单向RNN多一个隐藏层,6个独特的权值在每一个时步被重复利用,6个权值分别对应输入到向前和向后隐含层(w1,w3),隐含层到隐含层自己(w2,w5),向前和向后隐含层到输出层(w4,w6)。双向PNN时序在神经网络里的时序步骤如图所示。
在按照时间序列正向运算完之后,网络又从时间的最后一项反向地运算一遍,即把t3时刻的输入与默认值0一起生成反向的out3,把反向out3当成t2时刻的输入与原来的t2时刻输入一起生成反向out2;依此类推,直到第一个时序数据。
注意: 双向循环网络的输出是2个,正向一个,反向一个。最终会把输出结果通过concat并联在一起,然后交给后面的层来处理。
例如,数据输入[batch,nhidden],输出就会变成[batch,nhidden×2]。在大多数应用里,基于时间序列与上下文有关的、类似NLP中自动回答类的问题,一般都是使用双向LSTM+LSTM/RNN横向扩展来实现的,效果非常好。
基于神经网络的时序类分类CTC
CTC(Connectionist Temporal Classification)是语音辨识中的一个关键技术,通过增加一个额外的Symbol代表NULL来解决叠字问题。RNN的优势是在处理连续的数据,在基于连续的时间序列分类任务中,常常会使用CTC的方法。
该方法主要体现在处理loss值上,通过对序列对不上的label添加blank(空label)的方式,将预测的输出值与给定的label值在时间序列上对齐,通过交叉熵的算法求出具体损失值。比如在语音识别的例子中,对于一句语音有它的序列值及对应的文本,可以使用CTC的损失函数求出模型输出与label之间的loss,再通过优化器的迭代训练让损失值变小的方式将模型训练出来。
关于ctc_loss的算法细节,这里不做展开,后文还会有例子演示ctc_loss的真正用法


