一、场景
节点notready后大概5分钟才能重新调度pod,生产环境中高并发的场景下,一个副本5分钟无法提供服务,肯定会将请求压力转到其他副本,容易造成堵塞,严重的会阻断服务。如何缩短这个时间?
二、方案
k8s中有个准入控制器:DefaultTolerationSeconds。
此准入控制器基于 k8s-apiserver 的输入参数 default-not-ready-toleration-seconds 和 default-unreachable-toleration-seconds 为 Pod 设置默认的容忍度,以容忍 notready:NoExecute 和 unreachable:NoExecute 污点 (如果 Pod 尚未容忍 node.kubernetes.io/not-ready:NoExecute 和 node.kubernetes.io/unreachable:NoExecute 污点的话)。
default-not-ready-toleration-seconds 和 default-unreachable-toleration-seconds 的默认值是 5 分钟。
根据实际场景,可以修改此值。
三、测试
1.没修改参数时
发布一个pod,此时pod在k8s-node2节点
[root@k8s-master daemonset]# kubectl get pod -n test -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-854d5f75db-f9h89 1/1 Running 0 2m30s 10.244.169.143 k8s-node2 <none> <none>
停止k8s-node2的kubelet,使node notready
[root@k8s-node2 ~]# systemctl stop kubelet
[root@k8s-node2 ~]#
节点notready
[root@k8s-master ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 29d v1.20.13
k8s-node1 Ready <none> 29d v1.20.13
k8s-node2 NotReady <none> 29d v1.20.13
k8s-node3 Ready,SchedulingDisabled <none> 29d v1.20.13
稍等片刻,等pod重新调度,新pod被调度在节点k8s-node1上:
[root@k8s-master daemonset]# kubectl get pod -n test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-854d5f75db-f9h89 1/1 Terminating 0 50m 10.244.169.143 k8s-node2 <none> <none>
nginx-854d5f75db-r29rb 1/1 Running 0 3m54s 10.244.36.116 k8s-node1 <none> <none>
重点:如何判断节点notready5分钟后pod被调度
查看node的污点创建时间
[root@k8s-master ~]# kubectl get node k8s-node2 -o custom-columns=Name:.metadata.name,Taints:.spec.taints
Name Taints
k8s-node2 [map[effect:NoSchedule key:node.kubernetes.io/unreachable timeAdded:2023-03-09T09:27:52Z] map[effect:NoExecute key:node.kubernetes.io/unreachable timeAdded:2023-03-09T09:27:57Z]]
## effect=NoExcute污点添加时间是27分57秒
再看pod创建时间
[root@k8s-master daemonset]# kubectl describe pod nginx-854d5f75db-r29rb -n test
Name: nginx-854d5f75db-r29rb
Namespace: test
Priority: 0
Node: k8s-node1/192.168.0.38
Start Time: Thu, 09 Mar 2023 17:32:57 +0800 # pod启动时间是32分57秒
Labels: k8s.kuboard.cn/layer=gateway
k8s.kuboard.cn/name=nginx
pod-template-hash=854d5f75db
Annotations: cni.projectcalico.org/containerID: d0a0cd39f52fa3dfb65a6a0b710e78dd44b8a9c31780885a28ec56aa7a0cd07c
cni.projectcalico.org/podIP: 10.244.36.116/32
cni.projectcalico.org/podIPs: 10.244.36.116/32
Status: Running
IP: 10.244.36.116
。。。。。。
pod创建时间 - 污点添加时间=5分钟
2.把默认参数修改为30
编辑apiserver配置文件
[root@k8s-master daemonset]# vim /etc/kubernetes/manifests/kube-apiserver.yaml
##在command末尾添加
- --default-not-ready-toleration-seconds=30
- --default-unreachable-toleration-seconds=30
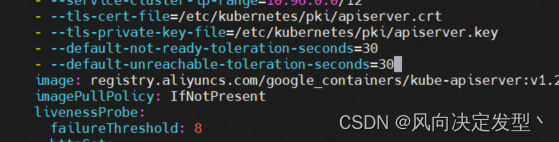
保存退出后,apiserver会自动重启。
另外,如果你的k8s集群是高可用集群,有多个master,那么所有master上的apiserver都要加这个参数
3.测试修改参数后的调度时间
启动k8s-node2上的kubelet:
[root@k8s-node2 ~]# systemctl start kubelet
目前pod在k8s-node1上:
[root@k8s-master daemonset]# kubectl get pod -n test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-854d5f75db-r29rb 1/1 Running 0 27m 10.244.36.116 k8s-node1 <none> <none>
停止k8s-node1的kubelet,使节点notready
[root@k8s-node1 ~]# systemctl stop kubelet
查看污点添加时间
[root@k8s-master ~]# kubectl get node k8s-node1 -o custom-columns=Name:.metadata.name,Taints:.spec.taints -w
Name Taints
k8s-node1 [map[effect:NoSchedule key:node.kubernetes.io/unreachable timeAdded:2023-03-09T10:21:48Z] map[effect:NoExecute key:node.kubernetes.io/unreachable timeAdded:2023-03-09T10:21:54Z]]
## 污点创建时间21分54秒
查看pod创建时间
[root@k8s-master daemonset]# kubectl get pod -n test -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-854d5f75db-4vd77 1/1 Running 0 6m21s 10.244.36.86 k8s-node2 <none> <none>
nginx-854d5f75db-v5p8h 1/1 Terminating 0 21m 10.244.169.151 k8s-node1 <none> <none>
[root@k8s-master daemonset]# kubectl describe pod nginx-854d5f75db-4vd77 -n test
Name: nginx-854d5f75db-4vd77
Namespace: test
Priority: 0
Node: k8s-node2/192.168.0.39
Start Time: Thu, 09 Mar 2023 18:22:24 +0800 # Pod创建时间22分24秒
Labels: k8s.kuboard.cn/layer=gateway
Pod创建时间-污点创建时间=22分24秒-21分54秒=30秒
配置生效。
4. 为什么有个pod是Terminating状态?
[root@k8s-master ~]# kubectl get pod -n test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-854d5f75db-4vd77 1/1 Running 0 13m 10.244.36.86 k8s-node1 <none> <none>
nginx-854d5f75db-v5p8h 1/1 Terminating 0 28m 10.244.169.151 k8s-node2 <none> <none>
k8s-node2上的kubelet停止,已经是notready状态,所以新pod创建后,老pod是删除不了的,一直处于Terminating状态,这时可以手动强制删除,或等节点正常后会自动删除。
强制删除
[root@k8s-master ~]# kubectl delete pod nginx-854d5f75db-v5p8h -n test --force --grace-period=0
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely.
pod "nginx-854d5f75db-v5p8h" force deleted
再次查询:
[root@k8s-master ~]# kubectl get pod -n test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-854d5f75db-4vd77 1/1 Running 0 17m 10.244.36.86 k8s-node1 <none> <none>
已经删除掉了。



不瞒你说,我最近正需要这个。
(#^.^#)