压测环境
部署方案:整个Ceph Cluster均在同一VPC中,结构如图:
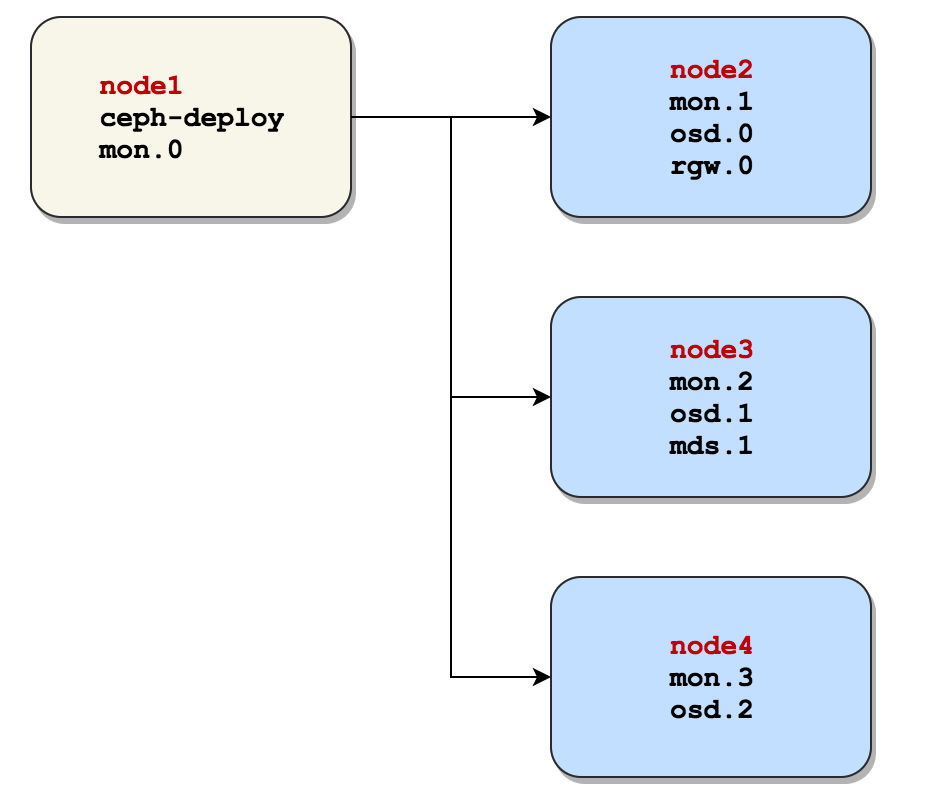
准备工作
查看ceph cluster的osd分布情况:
# ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-6 0 rack test-bucket
-5 0 rack demo
-1 0.86458 root default
-2 0.28819 host node2
0 0.28819 osd.0 up 1.00000 1.00000
-3 0.28819 host node3
1 0.28819 osd.1 up 1.00000 1.00000
-4 0.28819 host node4
2 0.28819 osd.2 up 1.00000 1.00000
使用 Test pool,此池为 64 个 PGs,数据存三份;
# ceph osd pool create test 64 64
pool 'test' created
# ceph osd pool get test size
size: 3
# ceph osd pool get test pg_num
pg_num: 64
Ceph osd 采用 xfs 文件系统(若使用 brtf 文件系统读写性能将翻 2 倍,但brtf不建议在生产环境使用);
Ceph 系统中的Block采用默认安装,为 64K;
性能测试客户端运行在node1上,在同一VPC下使用同一网段访问 Ceph 存贮系统进行数据读写;
本次测试中,发起流量的客户端位于Ceph Cluster中,故网络延时较小,真正生产环境中还需要考虑网络瓶颈。生产环境的网络访问图如下:
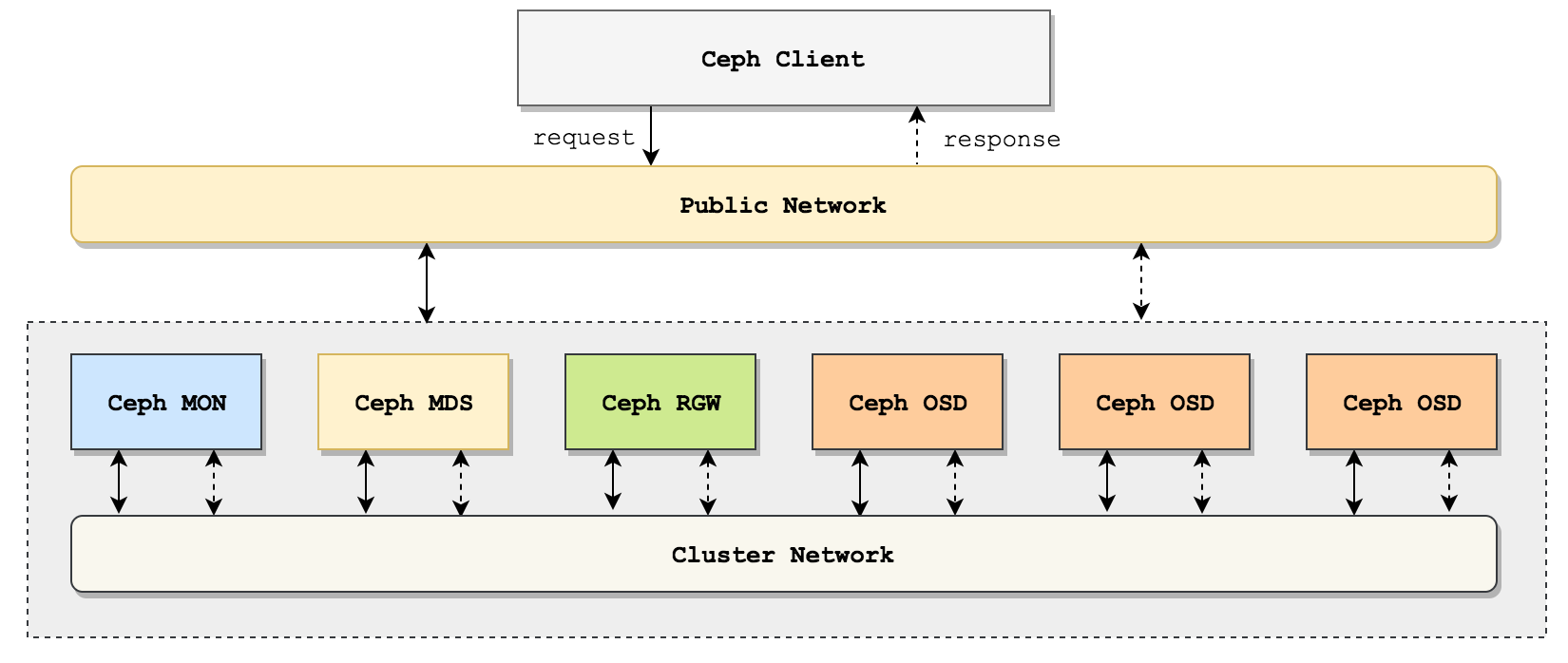
查看test pool默认配置:
# ceph osd dump | grep test
pool 12 'test' replicated size 3 min_size 2 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 37 flags hashpspool stripe_width 0
查看test poll资源占用情况:
# rados -p test df
pool name KB objects clones degraded unfound rd rd KB wr wr KB
test 0 0 0 0 0 0 0 0 0
total used 27044652 192
total avail 854232624
total space 928512000
rados bench基准测试
Ceph附带一个称为rados bench的内置基准测试工具,可以在池上测试Ceph集群的性能。rados bench工具支持写入、顺序读取和随机读取基准测试,并且它还允许清理临时基准数据。
rados bench 测试的主要是 Ceph 集群的 Raw Object Storage 性能(即 RADOS 层)。它直接与 OSD 交互,绕过了更高层的功能,比如 RBD(RADOS Block Device)或者 CephFS(Ceph File System),RBD 和 CephFS 都是建立在 RADOS 层之上的,rados bench 不会涉及它们的元数据操作或客户端缓存机制。
接下来我们对test池进行写60秒的测试,--no-cleanup写完之后不清里测试数据,后面的测试会用到这些测试数据。
该工具的语法为:rados bench -p -b -t --no-cleanup
pool_name:测试的存储池seconds:测试持续的秒数-b:block size,即块大小,默认为 4M-t:读/写并行数,默认为 16--no-cleanup表示测试完成后不删除测试用数据。在做读测试之前,需要使用该参数来运行一遍写测试来产生测试数据,在全部测试结束后可以运行 rados -p cleanup 来清理所有测试数据。
写性能测试
测试写性能
# rados bench -p test 60 write --no-cleanup
...
59 16 29893 29877 2025.28 1896 0.0255076 0.0315823
2025-01-10T17:29:53.131901+0800 min lat: 0.0105402 max lat: 0.127971 avg lat: 0.031586
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
60 15 30391 30376 2024.79 1996 0.0360623 0.031586
Total time run: 60.026
Total writes made: 30391
Write size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 2025.19
Stddev Bandwidth: 80.5031
Max bandwidth (MB/sec): 2212
Min bandwidth (MB/sec): 1776
Average IOPS: 506
Stddev IOPS: 20.1258
Max IOPS: 553
Min IOPS: 444
Average Latency(s): 0.0315902
Stddev Latency(s): 0.0109676
Max latency(s): 0.127971
Min latency(s): 0.0105402
root@node01:~#
数据写入时的平均带宽是2025MB/sec,最大带宽是2212MB,带宽标准差是80.5031(反应网络稳定情况)。
读性能测试
顺序读性能测试
# rados bench -p test 60 seq
...
59 16 27333 27317 1851.44 1640 0.00965061 0.0337838
2025-01-10T17:36:42.627226+0800 min lat: 0.00519118 max lat: 0.131774 avg lat: 0.0337879
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
60 7 27785 27778 1851.31 1844 0.0449936 0.0337879
Total time run: 60.0417
Total reads made: 27785
Read size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 1851.05
Average IOPS: 462
Stddev IOPS: 30.0378
Max IOPS: 528
Min IOPS: 379
Average Latency(s): 0.0337904
Max latency(s): 0.131774
Min latency(s): 0.00519118
以上测试数据可以看出:数据读取时的平均带宽是1851MB/sec,平均延时是0.03 sec,平均IOPS是462。
随机读性能测试
测试读性能
# rados bench -p test 60 rand
...
59 16 27055 27039 1832.62 1812 0.0487409 0.0341605
2025-01-10T17:33:01.620849+0800 min lat: 0.00393928 max lat: 0.11186 avg lat: 0.0341782
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
60 9 27489 27480 1831.45 1764 0.0241029 0.0341782
Total time run: 60.0634
Total reads made: 27489
Read size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 1830.67
Average IOPS: 457
Stddev IOPS: 20.2242
Max IOPS: 504
Min IOPS: 424
Average Latency(s): 0.0341901
Max latency(s): 0.11186
Min latency(s): 0.00393928
以上测试数据可以看出:数据读取时的平均带宽是1830MB/sec,平均延时是0.03 sec,平均IOPS是457。
测试数据清除
rados -p test cleanup
删除test池:
# ceph osd pool delete test test --yes-i-really-really-mean-it
pool 'test' removed
总结
- 随机读和顺序读,性能一样。
- ceph 针对大块文件的读写性能非常优秀,高达2GB/s。
- pool配置:2个副本比3个副本的性能高出很多;
- 若机器配置不算很差(4核8G以上),ceph很容易达到1G带宽的限制阀值,若想继续提升ceph性能,需考虑提升带宽阀值。
- 设置更多的PG值可以带来更好的负载均衡,但从测试来看,设置较大的PG值并不会提高性能。
- 将fileStore刷新器设置为false对性能有不错的提升。


