镜像集群之间的数据
We refer to the process of replicating data between Kafka clusters "mirroring" to avoid confusion with the replication that happens amongst the nodes in a single cluster. Kafka comes with a tool for mirroring data between Kafka clusters. The tool reads from one or more source clusters and writes to a destination cluster, like this:
我们指的是kafka集群之间复制数据“镜像”,为避免在单个集群中的节点之间发生复制混乱的。kafka附带了kafka集群之间的镜像数据的工具。该工具从一个源集群读取和写入到目标集群,像这样:
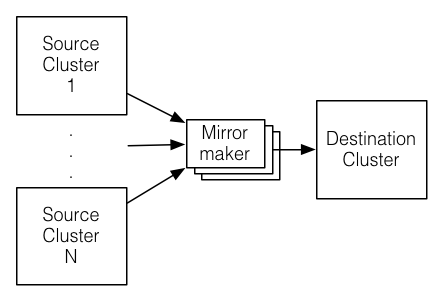
A common use case for this kind of mirroring is to provide a replica in another datacenter. This scenario will be discussed in more detail in the next section.
常见的用例是镜像在另一个数据中心提供一个副本。这种方案的将在下一节详细讨论。
You can run many such mirroring processes to increase throughput and for fault-tolerance (if one process dies, the others will take overs the additional load).
你可以运行很多这样的镜像进程来提高吞吐和容错性(如果某个进程挂了,则其他的进程会接管)
Data will be read from topics in the source cluster and written to a topic with the same name in the destination cluster. In fact the mirror maker is little more than a Kafka consumer and producer hooked together.
数据从源集群中的topic读取并将其写入到目标集群中相名的topic。事实上,镜像制作不比消费者和生产者连接要好。
The source and destination clusters are completely independent entities: they can have different numbers of partitions and the offsets will not be the same. For this reason the mirror cluster is not really intended as a fault-tolerance mechanism (as the consumer position will be different); for that we recommend using normal in-cluster replication. The mirror maker process will, however, retain and use the message key for partitioning so order is preserved on a per-key basis.
源和目标集群是完全独立的实体:分区数和offset可以都不相同,就是因为这个原因,镜像集群并不是真的打算作为一个容错机制(消费者位置是不同的),为此,我们推荐使用正常的集群复制。然而,镜像制造将保留和使用分区的消息key,以便每个键基础上保存顺序。
Here is an example showing how to mirror a single topic (named my-topic) from two input clusters:
下面是一个示例演示如何从两个输入集群镜像到一个topic(名为:my-topic):
> bin/kafka-run-class.sh kafka.tools.MirrorMaker
--consumer.config consumer-1.properties --consumer.config consumer-2.properties
--producer.config producer.properties --whitelist my-topic
Note that we specify the list of topics with the--whitelist option. This option allows any regular expression using Java-style regular expressions. So you could mirror two topics named A and B using--whitelist 'A|B'. Or you could mirror all topics using--whitelist '*'. Make sure to quote any regular expression to ensure the shell doesn't try to expand it as a file path. For convenience we allow the use of ',' instead of '|' to specify a list of topics.
注意,我们用 --whitelist 选项指定topic列表。此选项允许使用java风格的正则表达式。所以你可以使用--whitelist 'A|B' ,A和B是镜像名。或者你可以镜像所有topic。也可以使用--whitelist ‘*’镜像所有topic,为了确保引用的正则表达式不会被shell认为是一个文件路径,我们允许使用‘,’ 而不是’|’指定topic列表。
Sometime it is easier to say what it is that you don't want. Instead of using--whitelist to say what you want to mirror you can use--blacklist to say what to exclude. This also takes a regular expression argument.
你可以很容易的排除哪些是不需要的,可以用--blacklist来排除,目前--new.consumer不支持。
Combining mirroring with the configuration auto.create.topics.enable=true makes it possible to have a replica cluster that will automatically create and replicate all data in a source cluster even as new topics are added.
镜像结合配置auto.create.topics.enable=true,这样副本集群就会自动创建和复制。



请问,这属于一种迁移吗?
双活。
这个是主备吧 ,双活是两个集群相互同步,想请教一下如果两个集群都用这个模式来相互同步会不会有问题?
可以的。
另外主备的offset是保持一致,这个不是。