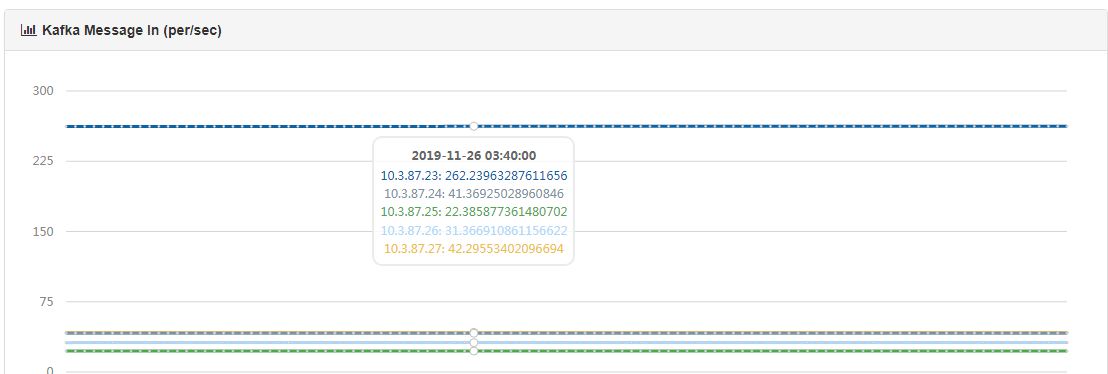
我发现每隔30多天。就会有节点落后过多。被踢出ISR。我该如何防止这种情况出现。调参数增加一个容忍时间或大小。我也想过。但最终还是会落后啊?我5个节点软硬都是一样的。参数配的也一样。 还有我如何查看落后的情况? 每次出现落后。我都会重点全部节点。问一下。是只需要重点落后的节点还是需要重点全部节点。 当然有些主题是0点节点落后。有些主点是2号节点落后。同一个节点在有的主题上是落后的,有的节点上没有落后。 我还发现0号机器的消息进入速率要远大于其他节点



落后是通过
replica.lag.max.messages配置控制,卡住是通过replica.lag.time.max.ms配置控制的参考:https://www.orchome.com/22
replica.lag.max.messages这个网上说0.10.0就取消了咧。replica.lag.time.max.ms是增加时间容忍。但还是有可能超过这个值。有其他的方法吗?怎么查看落后的情况呢?
是的,kafka的策略更纯粹了,你关心的落后问题也是一样,完全依靠
replica.lag.time.max.ms:如果一个follower在有一个时间窗口内没有发送任何fetch请求,leader就会把这个follower从ISR(in-sync replicas)移除,并认为它已挂掉。关注一下,那台跟不上的节点,是否某些资源已经到达了瓶颈(网络优先),或者是否配置了副本的资源的限制。
我有两个节点划的数据目录要少一点。网络上应该都是一样的
你的答案