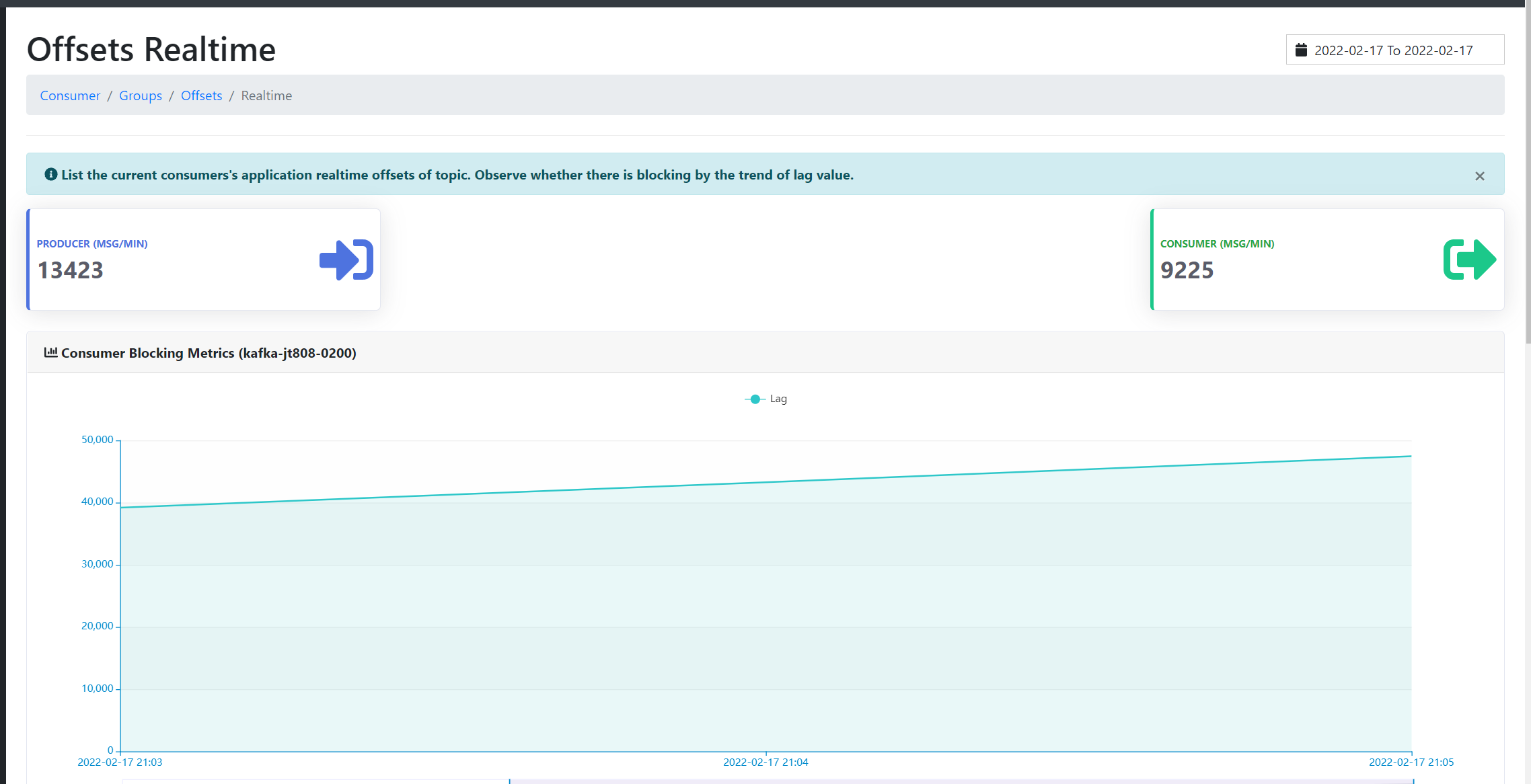
观察图:
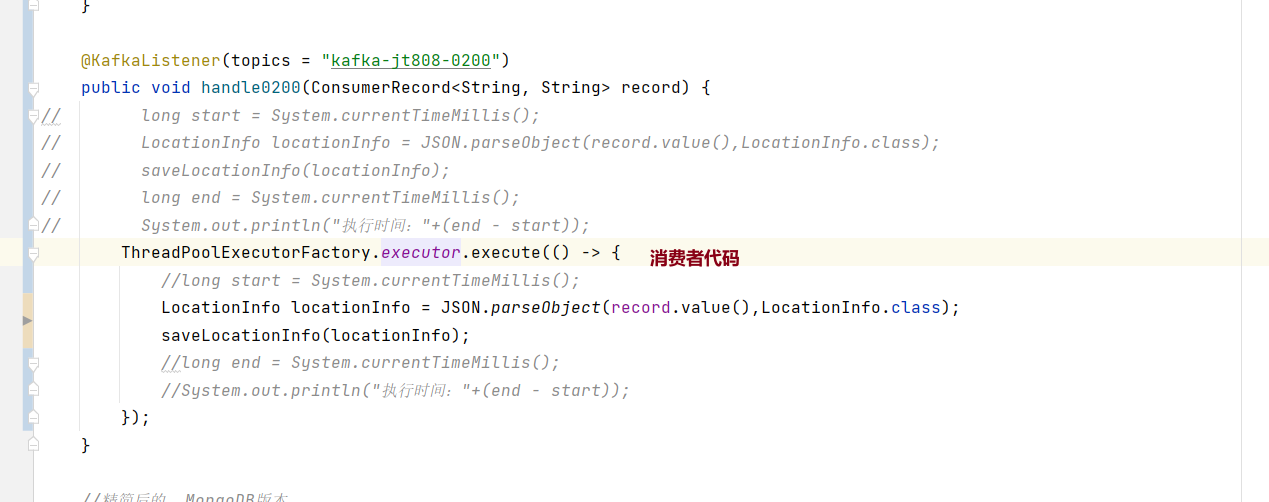
消费者代码:
感觉这点并发量,单个消费者应该可以通过优化解决掉吧。
我不清楚你消费者对获取到的消息做了什么,但一般速度都是卡在程序处理上,而影响的消费者速度。
1、kafka默认是批量拉取消息的(一次拉取约2000条,是根据消息大小的),所以一般瓶颈不在消费者拉取消息这块,一般是处理能力的问题,就是你拉取到了2000条给程序,程序处理这2000需要多久,然后kafka才会拉取下一个批次。
2、如果你想减少lag,你可以通过增加topic分区数和增加更多消费者来解决。
我只打印一下消息,一分钟才七八千,按理说一个system.out.print不应该有太大的消耗的。
我的配置如下:
kafka: bootstrap-servers: 39.105.175.129:9092 # kafka集群信息 producer: # 生产者配置 retries: 3 # 设置大于0的值,则客户端会将发送失败的记录重新发送 batch-size: 16384 #16K buffer-memory: 33554432 #32M acks: 1 # 指定消息key和消息体的编解码方式 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer consumer: group-id: hujunjie # group-id: zhTestGroup # 消费者组 enable-auto-commit: true # 关闭自动提交 auto-offset-reset: earliest # 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer listener: ack-mode: RECORD
@KafkaListener(topics = "kafka-jt808-0200") public void handle0200(ConsumerRecord<String, String> record) { ThreadPoolExecutorFactory.executor.execute(() -> { String value = record.value(); System.out.println("000 " + value); }); }
@KafkaListener(topics = "kafka-jt808-0200") public void handle0200(ConsumerRecord<String, String> record) { System.out.println("000 " + record.value()); }
1、去掉线程池,只打印,你在试试,线程池会一直创建线程,影响速度。2、缩小每条记录的大小,如果你只测试条数的话。
另外,你的kafka部署在阿里云,你的程序如果在本地,那么也会因为带宽问题,影响的,毕竟是走公网的。
嗯嗯 也可能每个消息有点长,我去改一下生产者,改短一下 试试
你这并发一上来 你这线程池 吃的住?
您有什么办法吗
看这个saveLo*这个方法单线程的情况下一秒能处理多少(主要的是你这方法的执行速度) 然后在批量消费合理分配线程你现在这种方式消费数据量大的时候 kafka确实能做到秒ack(因为你异步处理) 压力全在线程池 如果线程池配置的是阻塞队列那就可以能丢数据,如果是非阻塞的 就不知道几百万下来 你内存能不能吃的住 同样的数据全部堆在内存队列安全系数很低
您看一下我另一个帖子 不知道您有没有遇到过类似的问题
找不到想要的答案?提一个您自己的问题。
0 声望
这家伙太懒,什么都没留下



我不清楚你消费者对获取到的消息做了什么,但一般速度都是卡在程序处理上,而影响的消费者速度。
1、kafka默认是批量拉取消息的(一次拉取约2000条,是根据消息大小的),所以一般瓶颈不在消费者拉取消息这块,一般是处理能力的问题,就是你拉取到了2000条给程序,程序处理这2000需要多久,然后kafka才会拉取下一个批次。
2、如果你想减少lag,你可以通过增加topic分区数和增加更多消费者来解决。
我只打印一下消息,一分钟才七八千,按理说一个system.out.print不应该有太大的消耗的。
我的配置如下:
kafka: bootstrap-servers: 39.105.175.129:9092 # kafka集群信息 producer: # 生产者配置 retries: 3 # 设置大于0的值,则客户端会将发送失败的记录重新发送 batch-size: 16384 #16K buffer-memory: 33554432 #32M acks: 1 # 指定消息key和消息体的编解码方式 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer consumer: group-id: hujunjie # group-id: zhTestGroup # 消费者组 enable-auto-commit: true # 关闭自动提交 auto-offset-reset: earliest # 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer listener: ack-mode: RECORD消费者的代码
@KafkaListener(topics = "kafka-jt808-0200") public void handle0200(ConsumerRecord<String, String> record) { ThreadPoolExecutorFactory.executor.execute(() -> { String value = record.value(); System.out.println("000 " + value); }); }@KafkaListener(topics = "kafka-jt808-0200") public void handle0200(ConsumerRecord<String, String> record) { System.out.println("000 " + record.value()); }1、去掉线程池,只打印,你在试试,线程池会一直创建线程,影响速度。
2、缩小每条记录的大小,如果你只测试条数的话。
另外,你的kafka部署在阿里云,你的程序如果在本地,那么也会因为带宽问题,影响的,毕竟是走公网的。
嗯嗯 也可能每个消息有点长,我去改一下生产者,改短一下 试试
你这并发一上来 你这线程池 吃的住?
您有什么办法吗
看这个saveLo*这个方法单线程的情况下一秒能处理多少(主要的是你这方法的执行速度) 然后在批量消费合理分配线程
你现在这种方式消费数据量大的时候 kafka确实能做到秒ack(因为你异步处理) 压力全在线程池 如果线程池配置的是阻塞队列那就可以能丢数据,如果是非阻塞的 就不知道几百万下来 你内存能不能吃的住 同样的数据全部堆在内存队列安全系数很低
您看一下我另一个帖子 不知道您有没有遇到过类似的问题
你的答案