生产环境发现不定时 Java 应用出现 coredump 故障,测试环境不定时出现写入 /cgroup/memory报 no space left on device的故障,导致整个 kubernetes node 节点无法使用。设置会随着堆积的 cgroup 越来越多,docker ps 执行异常,直到把内存吃光,机器挂死。
报错:
kubelet.ns-k8s-node001.root.log.ERROR.20180214-113740.15702:1593018:E0320
04:59:09.572336 15702 remote_runtime.go:92] RunPodSandbox from runtime
service failed: rpc error: code = Unknown desc = failed to start sa
ndbox container for pod "osp-xxx-com-ljqm19-54bf7678b8-bvz9s": Error
response from daemon: oci runtime error: container_linux.go:247:
starting container process caused "process_linux.go:258: applying
cgroup configuration for process caused \"mkdir
/sys/fs/cgroup/memory/kubepods/burstable/podf1bd9e87-1ef2-11e8-afd3-fa163ecf2dce/8710c146b3c8b52f5da62e222273703b1e3d54a6a6270a0ea7ce1b194f1b5053:
no space left on device\""
或者
Mar 26 18:36:59 ns-k8s-node-s0054 kernel: SLUB: Unable to allocate
memory on node -1 (gfp=0x8020) Mar 26 18:36:59 ns-k8s-noah-node001
kernel: cache:
ip6_dst_cache(1995:6b6bc0c9f30123084a409d89a300b017d26ee5e2c3ac8a02c295c378f3dbfa5f),
object size: 448, buffer size: 448, default order: 2, min order: 0
该问题发生前后,进行过 kubernetes 1.6 到 1.9 的升级工作。排查了好久才定位到问题与 kubernetes 、内核有关。
1. 对比测试结果
使用同样的测试方法,结果为:
1)使用初次部署 k8s 1.6 版本测试,没有出现 cgroup memory 遗漏问题;
2)从 k8s 1.6 升级到 1.9 后,测试没有出现 cgroup memory 遗漏问题;
3)重启 kubelet 1.9 node 节点重启,再次测试,出现 cgroup memory 遗漏问题。
对比 k8s 1.6 和 1.9 创建的 POD 基础容器和业务容器,runc、libcontainerd、docker inspect 的容器 json 参数都一致,没有差异。
为什么同样是 k8s 1.9(其他 docker、kernel 版本一致)的情况下,结果不一样呢?重启的影响是?
2. 问题重现
对于 cgroup memory 报 no space left on device ,是由于 cgroup memory 存在 64k(65535 个)大小的限制。
采用下面的测试方式,可以发现在删除 pod 后,会出现 cgroup memory 遗漏的问题。该测试方法通过留空 99 个 系统 cgroup memory 位置,来判断引起问题的原因是由于 pod container 导致的。
1)填满系统 cgroup memory
$ sudo uname -r
3.10.0-514.10.2.el7.x86_64
$ sudo kubelet --version Kubernetes 1.9.0
$ sudo mkdir /sys/fs/cgroup/memory/test
$ sudo for i in `seq 1 65535`;do mkdir /sys/fs/cgroup/memory/test/test-${i}; done
$ sudo cat /proc/cgroups |grep memory memory 11 65535 1
把系统 cgroup memory 填到 65535 个。
2)腾空 99 个 cgroup memory
$ sudo for i in `seq 1 100`;do rmdir /sys/fs/cgroup/memory/test/test-${i} 2>/dev/null 1>&2; done
$ sudo mkdir /sys/fs/cgroup/memory/stress/
$ sudo for i in `seq 1 100`;do mkdir /sys/fs/cgroup/memory/test/test-${i}; done
mkdir: cannot create directory ‘/sys/fs/cgroup/memory/test/test-100’: No space left on device
$ sudo for i in `seq 1 100`;do rmdir /sys/fs/cgroup/memory/test/test-${i}; done
$ sudo cat /proc/cgroups |grep memory
memory 11 65436 1
在写入第 100 个的时候提示无法写入,证明写入了 99 个。
3)创建一个 pod 到这个 node 上,查看占用的 cgroup memory 情况
每创建一个 pod ,会占用 3 个 cgroup memory 目录:
$ sudo ll /sys/fs/cgroup/memory/kubepods/pod0f6c3c27-3186-11e8-afd3-fa163ecf2dce/
total 0
drwxr-xr-x 2 root root 0 Mar 27 14:14 6d1af9898c7f8d58066d0edb52e4d548d5a27e3c0d138775e9a3ddfa2b16ac2b
drwxr-xr-x 2 root root 0 Mar 27 14:14 8a65cb234767a02e130c162e8d5f4a0a92e345bfef6b4b664b39e7d035c63d1
这时再次创建 100 个 cgroup memory ,因为 pod 占用了 3 个,会出现 4 个无法成功:
$ sudo for i in `seq 1 100`;do mkdir /sys/fs/cgroup/memory/test/test-$i; done
mkdir: cannot create directory ‘/sys/fs/cgroup/memory/test/test-97’: No space left on device <-- directory used by pod
mkdir: cannot create directory ‘/sys/fs/cgroup/memory/test/test-98’: No space left on device
mkdir: cannot create directory ‘/sys/fs/cgroup/memory/test/test-99’: No space left on device
mkdir: cannot create directory ‘/sys/fs/cgroup/memory/test/test-100’: No space left on device
$ sudo cat /proc/cgroups
memory 11 65439 1
写入到的 cgroup memory 增加到 65439 个。
4)删掉测试 pod ,看看 3 个占用的 cgroup memory 是否有释放
看到的结果:
$ sudo cat /proc/cgroups
memory 11 65436 1
$ sudo for i in `seq 1 100`;do mkdir /sys/fs/cgroup/memory/test/test-$i; done
mkdir: cannot create directory ‘/sys/fs/cgroup/memory/test/test-97’: No space left on device
mkdir: cannot create directory ‘/sys/fs/cgroup/memory/test/test-98’: No space left on device
mkdir: cannot create directory ‘/sys/fs/cgroup/memory/test/test-99’: No space left on device
mkdir: cannot create directory ‘/sys/fs/cgroup/memory/test/test-100’: No space left on device
可以看到,虽然 cgroup memory 减少到 65536 ,似乎 3 个位置释放了。但实际上测试结果发现,并不能写入,结果还是 pod 占用时的无法写入 97-100 。
这就说明,cgroup memory 数量减少,但被 pod container 占用的空间没有释放。
反复验证后,发现随着 pod 发布和变更的增加,该问题会越来越严重,直到把整台机器的 cgroup memory 用完。
$ cat /proc/cgroups
subsys_name hierarchy num_cgroups enabled
cpuset 10 229418 1 -- 但 cpuset 数量很恐怖
cpu 6 118 1
cpuacct 6 118 1
memory 7 109 1 -- 看上去不多,实际没有释放空间的
devices 3 229504 1
freezer 5 32 1
net_cls 4 32 1
blkio 9 118 1
perf_event 11 32 1
hugetlb 2 32 1
pids 8 32 1
net_prio 4 32 1
3. 问题根源
经过大量的测试和对比分析,在两个 k8s 1.9 环境中 kubelet 创建的 /sys/fs/cgroup/memory/kubepods 差异,发现:
没问题的:
[root@k8s-node01 kubepods]# cat memory.kmem.slabinfo
cat: memory.kmem.slabinfo: Input/output error
有问题的:
[root@k8s-node01 kubepods]# cat memory.kmem.slabinfo
slabinfo -version: 2.1
name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata
> <active_slabs> <num_slabs> <sharedavail>
也就是说,在有问题的环境下,cgroup kernel memory 特性被激活了。
关于 cgroup kernel memory,在 kernel-doc 中有如下描述:
$ vim /usr/share/doc/kernel-doc-3.10.0/Documentation/cgroups/memory.txt
2.7 Kernel Memory Extension (CONFIG_MEMCG_KMEM)
With the Kernel memory extension, the Memory Controller is able to limit the amount of kernel memory used by the system.
Kernel memory is fundamentally different than user memory, since it can't be swapped out,
which makes it possible to DoS the system by consuming too much of this precious resource.
kernel memory won't be accounted at all until limit on a group is set. This allows for existing
setups to continue working without disruption. The limit cannot be set if the cgroup have
children, or if there are already tasks in the cgroup. Attempting to set the limit under those
conditions will return -EBUSY. When use_hierarchy == 1 and a group is accounted,
its children will automatically be accounted regardless of their limit value.
After a group is first limited, it will be kept being accounted until it is removed.
The memory limitation itself, can of course be removed by writing -1 to
memory.kmem.limit_in_bytes. In this case, kmem will be accounted, but not limited.
这是一个 cgroup memory 的扩展,用于限制对 kernel memory 的使用。但该特性在老于 4.0 版本中是个实验特性,若使用 docker run 运行,就会提示:
$ sudo docker run -d --name test001 --kernel-memory 100M registry.vclound.com:5000/hyphenwang/sshdserver:v1
WARNING: You specified a kernel memory limit on a kernel older than 4.0. Kernel memory limits are experimental on older kernels, it won't work as expected and can cause your system to be unstable.
$ cat /sys/fs/cgroup/memory/docker/eceb6dfba2c64a783f33bd5e54cecb32d5e64647439b4932468650257ea06206/memory.kmem.limit_in_bytes
104857600
经过反复验证,当使用 docker run --kernel-memory 参数启动的容器,在删除后也不会释放 cgroup memory 占用的位置 ,存在同样的问题。
基于该现象,对比 kubernetes 1.6 和 kubernetes 1.9 对 cgroup kernel memory 设置的差异。 在k8s 1.9 vendor库中,少了if d.config.KernelMemory != 0 { 这行代码的判断, 而在k8s的Github,1.6.4版本在官方的runc/libcontainerd增加了这行代码,但在1.9.0删掉了,导致默认就使用kmem 。
$ git diff remotes/origin/vip_v1.6.4.3 remotes/origin/vip_v1.9.0 -- vendor/github.com/opencontainers/runc/libcontainer/cgroups/fs/memory.go
@@ -29,14 +35,18 @@ func (s *MemoryGroup) Apply(d *cgroupData) (err error) {
path, err := d.path("memory")
if err != nil && !cgroups.IsNotFound(err) {
return err
+ } else if path == "" {
+ return nil
}
if memoryAssigned(d.config) {
- if path != "" {
+ if _, err := os.Stat(path); os.IsNotExist(err) {
if err := os.MkdirAll(path, 0755); err != nil {
return err
}
- }
- if d.config.KernelMemory != 0 { // 删除了这行的判断,使得 1.9 默认就 enable cgroup kernel memory 特性
+ // Only enable kernel memory accouting when this cgroup
+ // is created by libcontainer, otherwise we might get
+ // error when people use `cgroupsPath` to join an existed
+ // cgroup whose kernel memory is not initialized.
if err := EnableKernelMemoryAccounting(path); err != nil {
return err
}
这就引发了 cgroup memory 也不能释放的问题(与通过 docker run --kernel-memory 打开的情况一样。)
其实根据 libcontainerd 推荐的 kernel 4.3 以上版本,打开 cgroup kernel memory 应该也是没问题的。可惜我们使用的kernel版本是3.10.0-514.16.1.el7.x86_64,kernel memory在这个版本是不稳定的。因此让我们踩了这个坑。
经验证,CentOS 7.4(3.10.0-693.11.1.el7)存在同样的问题。
4. 寻根问底
附上同事对该问题在 kernel 中追踪的结果。
memcg是Linux内核中用于管理cgroup中kernel 内存的模块,整个生命周期应该是跟随cgroup的,但是当在3.10.0-514.10.2.el7版本中,一旦开启了kmem_limit就可能会导致不能彻底删除memcg和对应的cssid。
在创建过程中,如果我们设定了kmem_limit就会激活memcg
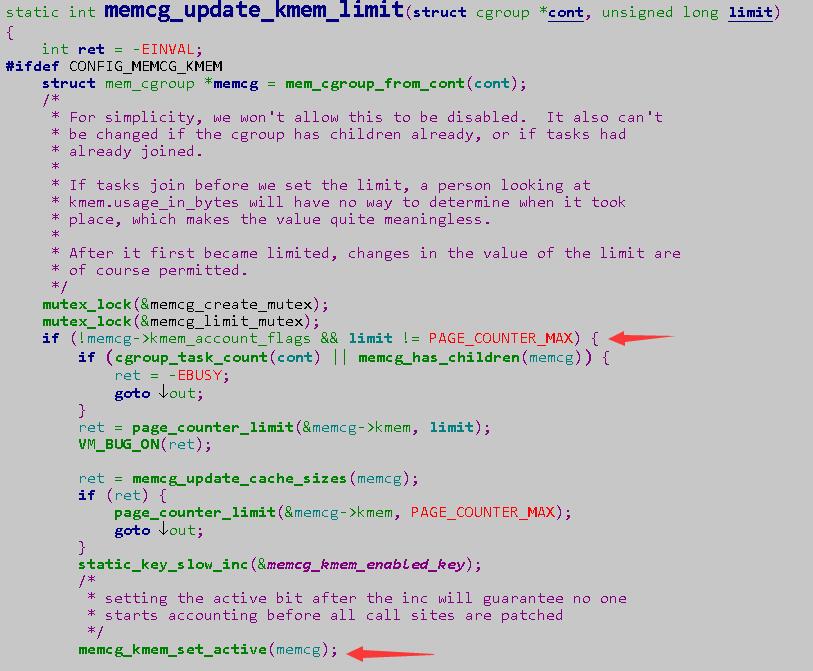
memcg和cssid的释放的调用链很长,其中在这个过程中,mem_cgroup_css_free的过程中会调用kmem_cgroup_destroy
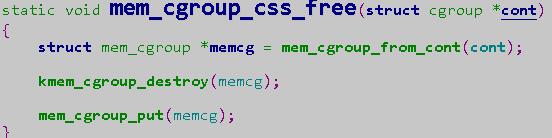
而kmem_cgroup_destroy函数会检查memcg是否还占用memory,如果发现还占用,就不会调用mem_cgroup_put函数:
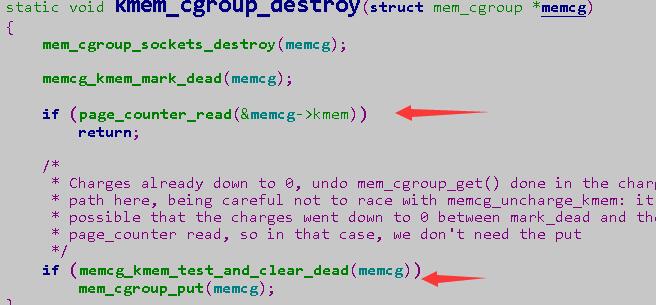
而mem_cgroup_put函数会将memcg的refcnt减去1,并查看是否等于0,如果为0即表示没有其他东西引用memcg,memcg可以放心释放
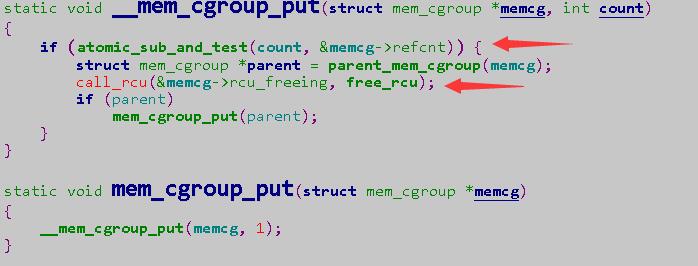
可惜当开启了kmem_limit后,这个refcnt不会等于0,导致永远无法调用到free_rcu去释放cssid。
5. 解决问题
经过以上分析,造成该故障的原因,是由于 kubelet 1.9 激活了 cgroup kernel-memory 特性,而在 CentOS 7.3 kernel 3.10.0-514.10.1.el7.x86_64 中对该特性支持不好。
导致删除容器后,仍有对 cgroup memory 的占用,没有执行 free_css_id() 函数的操作。
解决方式,就是修改 k8s 1.9 代码,再次禁止设置 cgroup kernel-memory 配置,保持关闭状态。
6. 疑问
为什么同样是 k8s 1.9 的版本,在不同的测试中没有问题
原因是第一次的 k8s 1.9 是在原来 k8s 1.6 的环境中,通过升级 kubelet 版本来测试的。
而 /sys/fs/cgroup/kubepods 是由 k8s 1.6 创建的,升级到 k8s 1.9 后,启动服务时,判断到该路径已经存在,就没有再创建新的。
所以,也就没有激活 cgroup kernel-memory 特性。
接下来创建的 POD 会继承该路径的 cgroup memory 属性,也没有激活 cgroup kernel-memoy ,所以没有引发问题。
相反,在重启 k8s 1.9 node 后,kubelet 新建了 /sys/fs/cgroup/kubepods ,激活了 cgroup kernel-memoy ,导致后续的 POD 在删除时也有问题。



经过以上分析,造成该故障的原因,是由于 kubelet 1.9 激活了 cgroup kernel-memory 特性,而在 CentOS 7.3 kernel 3.10.0-514.10.1.el7.x86_64 中对该特性支持不好。
导致删除容器后,仍有对 cgroup memory 的占用,没有执行 free_css_id() 函数的操作。
解决方式,就是修改 k8s 1.9 代码,再次禁止设置 cgroup kernel-memory 配置,保持关闭状态。
你的答案